In today’s dynamic cloud landscape, maximizing the value of your AWS investment is crucial for staying competitive and efficient. That’s where 3HTP Modernization and Optimization Assessment comes in. This service comprehensively analyzes your AWS infrastructure, resources, and services, delving deep into your account to identify optimization opportunities. Our team of experts, including seasoned AWS architects, conducts a live analysis session with you to ensure a personalized and thorough evaluation.
This document summarizes the activities and benefits that GEMA, along with many others, achieved by executing the activities with the help and expertise of our team. Don’t let inefficiencies drain your resources. Let our AWS Resource Optimization Assessment service help you unlock the full potential of your AWS environment, improve efficiency, and reduce costs.
About the customer
GEMA a Chilean web solutions company migrated their AWS services from São Paulo to Virginia for cost & performance gains. 3HTP analysis identified optimization areas, including migrating all the resources to another region, optimizing EC2/RDS instances, and implementing CloudFront for static content. Leveraging economies of scale in Virginia reduced transfer costs & enhanced content delivery for GEMA’s user base.
Customer Challenge
GEMA deployed most of its AWS services in the São Paulo region (sa-east-1). This decision was driven by the perception that proximity to Latin America would result in lower costs and reduced latency compared to regions in the United States.
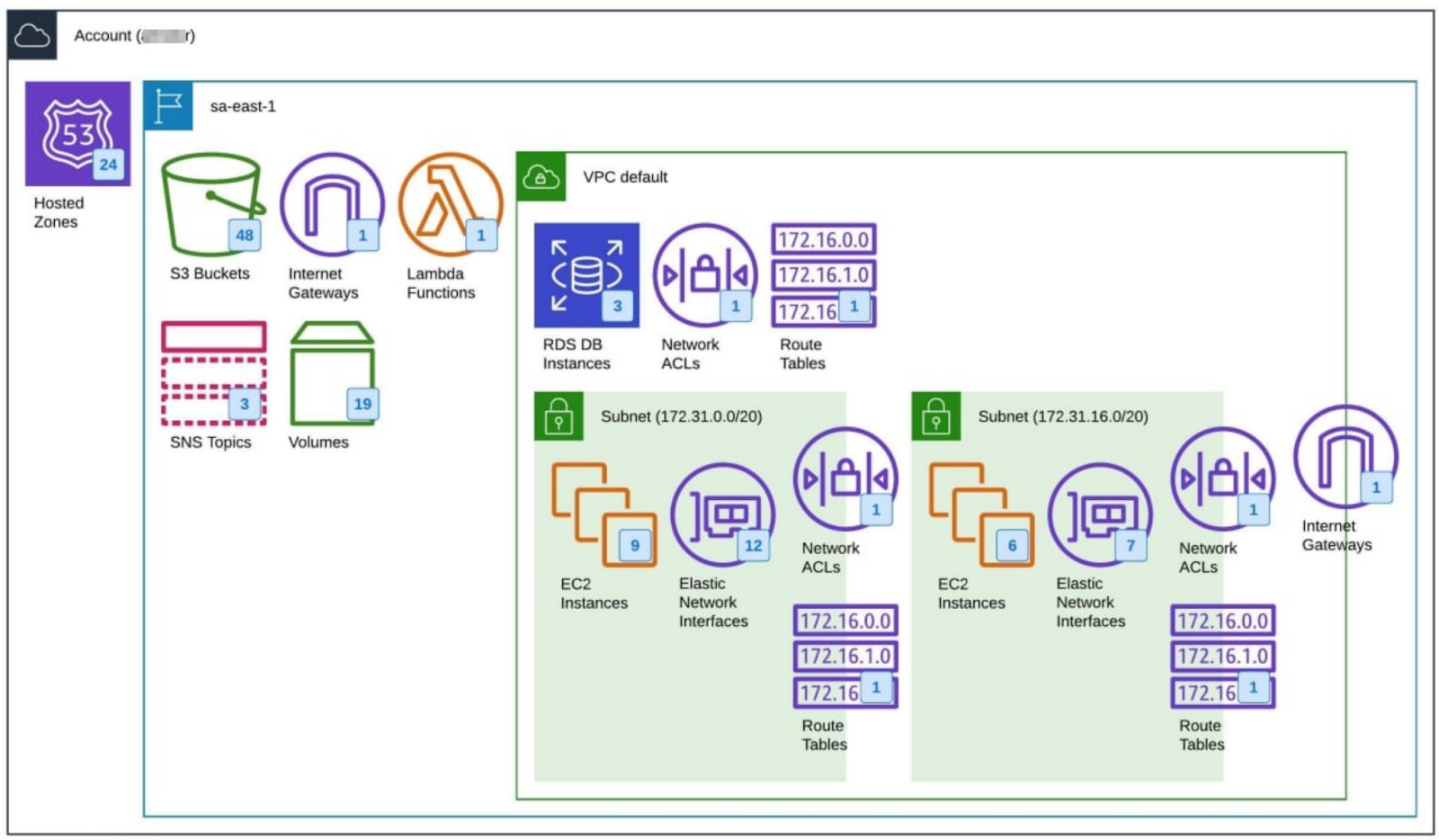
At the time of the 3HTP optimization report, GEMA’s AWS environment comprised 138 AWS resources, with primary billing expenses in Data Transfer, Amazon S3, Amazon EC2 instances, and Amazon RDS databases.
3HTP AWS Optimization Project
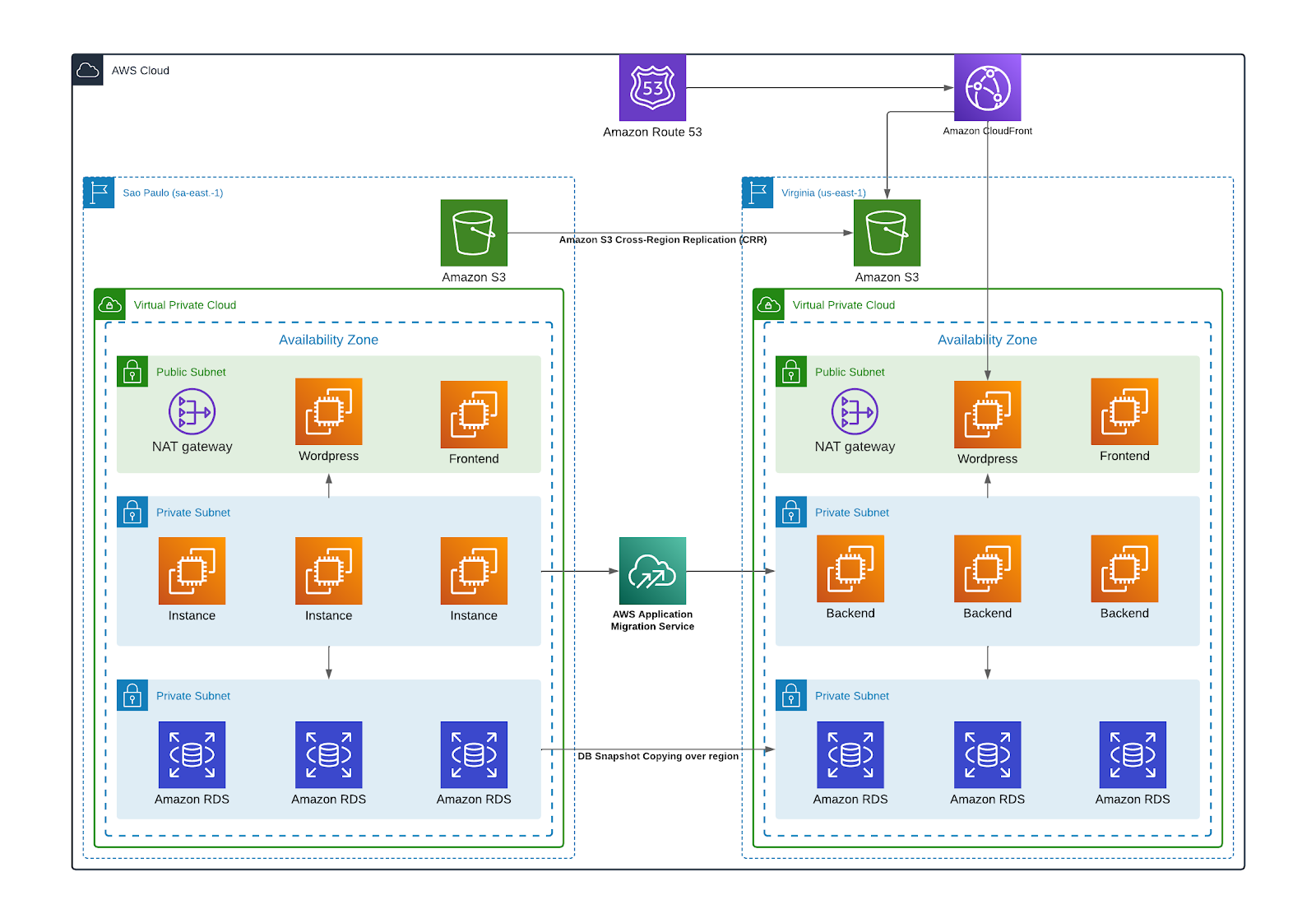
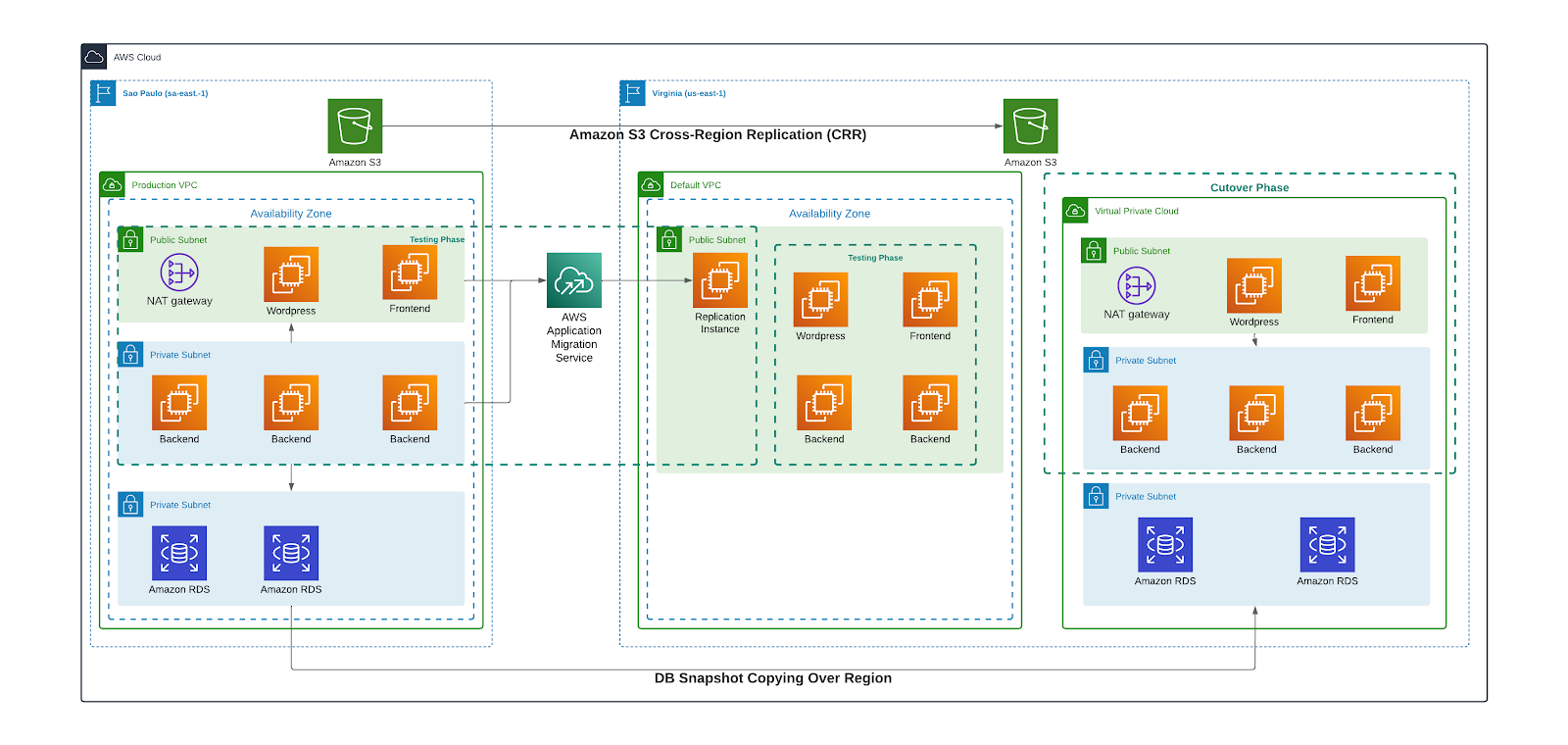
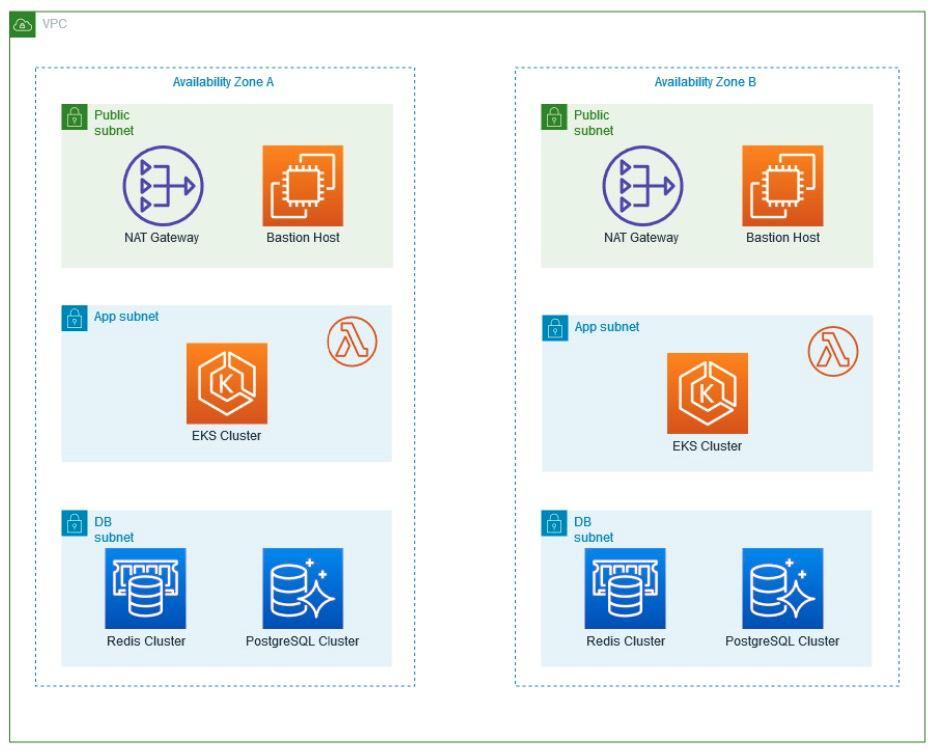
The following high-level architecture comprised the technical solution implemented with GEMA:
The following are the activities defined in the 3HTP optimization assessment which leads us to execute the project in three phases:
Migration of Compute and Database resources
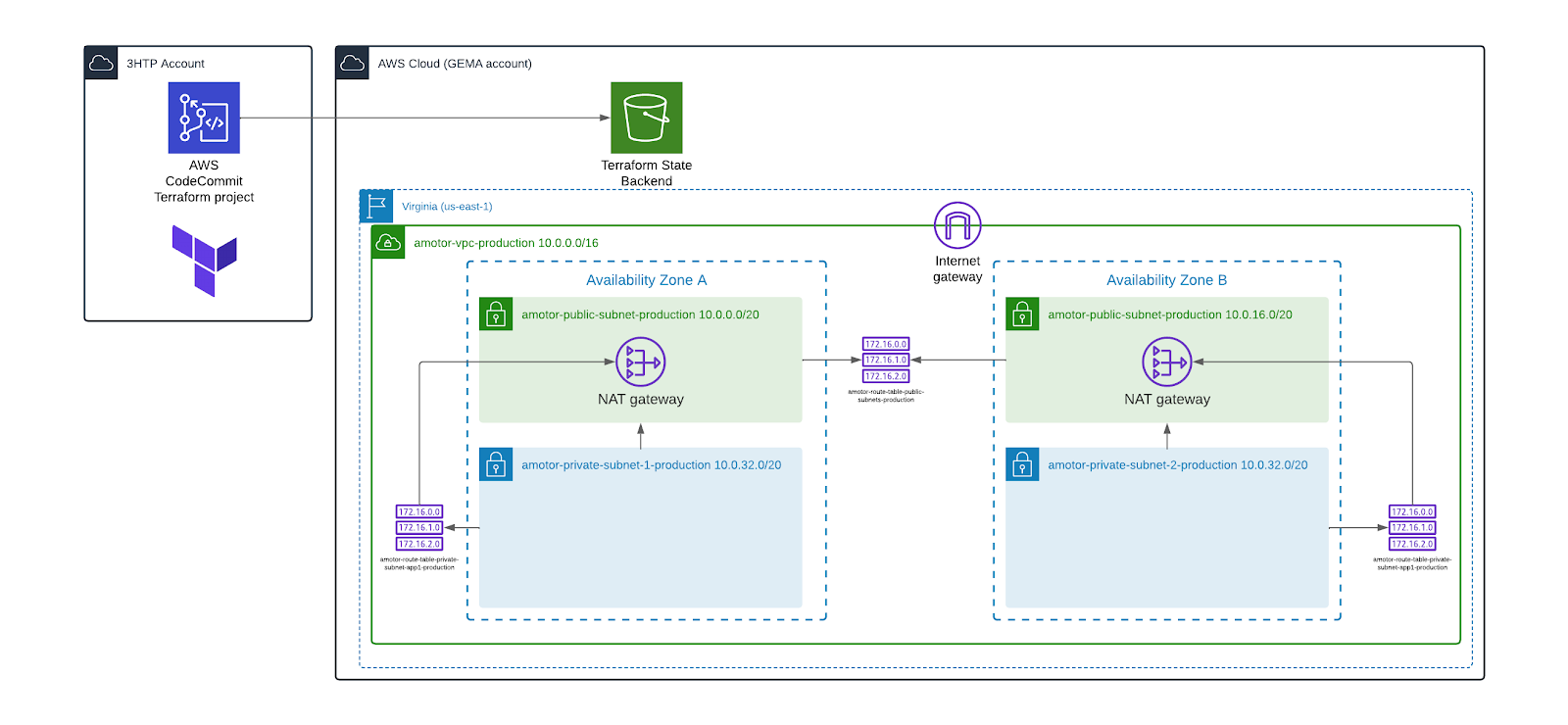
We start by creating a new landing zone in North Virginia region by leveraging Terraform as an Infrastructure as Code(IaC) tool which helps us quickly deploy the new North Virginia Amazon VPC and all networking resources (including subnets, route tables, NAT gateways, security groups, etc)
A two-wave migration was decided with GEMA’s team to ensure the high-priority instances will be migrated in the first wave. The following activities were performed to execute the migration:
Initial Sync and Replication of Amazon EC2 Instances:
The replication process was executed by utilizing AWS Application Migration Service (AWS MGN), the AWS MGN replication agent was installed and configured on each instance, the process was monitored in the AWS MGN dashboard in the Virginia region by confirming the initial sync of every source server.
Test of replicated Amazon EC2 instances:
AWS MGN helps us perform non-disruptive tests before cutover by quickly deploying test instances in a public subnet in the VPC Staging Area. A series of tests were executed in the testing VPC with the help of the GEMA technical team to ensure that the replicated instances could start and run the applications or processes deployed in every instance.
Cutover of replicated Amazon EC2 instances
When every Amazon EC2 was tested maintenance windows were requested and together with GEMA, the cutover process was applied to every one of the Amazon EC2 instances. This process was executed in two waves. This allows GEMA to migrate transparently to the region with minimal downtime.
Migration of Amazon RDS databases
Amazon RDS snapshot copy functionality across AWS regions was the method chosen to execute the migration process of Amazon RDS instances between regions, this method satisfied GEMA requirements and led us to recreate Amazon RDS in Virginia in a short maintenance window.
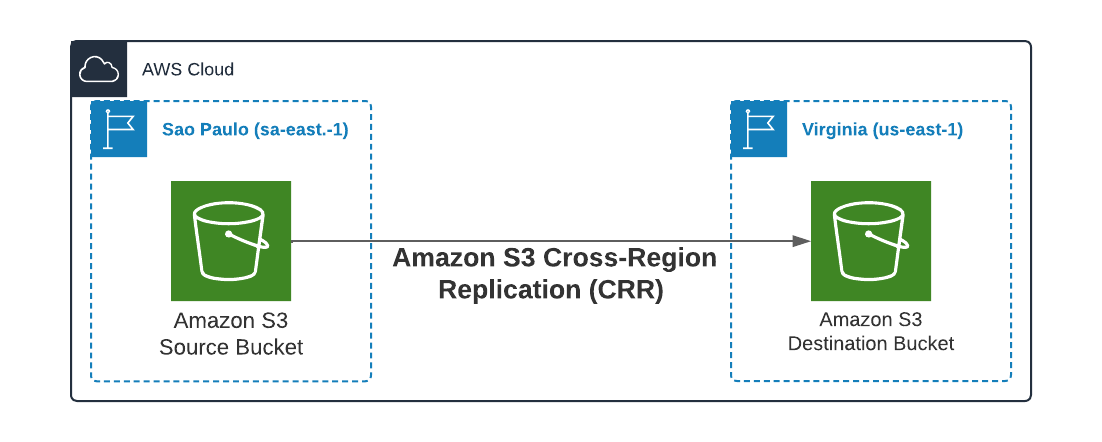
Amazon S3 Data replication
Amazon S3 Cross-Region Replication (CRR) was used to copy GEMA’s objects to Virginia. A lifecycle rule was applied in the source bucket to erase all objects when the replication finished.
Resource Optimization
The following activities were performed in this phase:
Amazon EBS optimization
Some Amazon EBS was running in provisioned IOPs (io1) configured using a small number of IOPs comparable to or inferior to general-purpose type volumes. Amazon EBS volumes were replicated via AWS MGN, the volumes were updated to use general-purpose last version (gp3) volume types which reduced costs and improved maximum throughput per volume.
Amazon EC2 Instance Type and Right-sizing Optimization
All instances were reviewed and tuned to their right size based on AWS Cloudwatch compute and memory resource usage, the t2 instances were upgraded/changed to the t3 family to reduce costs and upgrade to the last generation.
Amazon Cloudfront implementation
An Amazon CloudFront distribution was implemented to reduce AWS Data transfer costs associated with consuming the image files stored in AWS buckets
Result and benefits
AWS Application Migration Service (MGN) helps plan and execute an Amazon EC2 instance migration between regions with a centralized platform for application testing and cutover activities this workflow helps GEMA achieve minimal downtime.
The implementation of a Cloudfront distribution in front of WordPress deployment enhances the performance, cost-effectiveness and reduces the server load by offering streamlined integration between images hosted on Amazon S3 and the origin.
Amazon EC2 and Amazon RDS instance right-sizing improve GEMA instances performance by upgrading to last-generation instances.
AWS Optimization project helps GEMA achieve the following savings in their monthly bill:
~ 49% Cost savings on Amazon EC2 Instances and Amazon RDS
~ 15% Cost savings on data transfer and content delivery
Many organizations are focused on undertaking technology upgrades, and willing to improve their internal processes and project execution, to deliver superior experiences in performance, availability, and efficiency to their customers. However, tackling a technology upgrade, especially in the cloud environment, goes beyond mere willingness; it involves a solid commitment at both the organizational and managerial levels, aimed at implementing improvements that will be truly fruitful.
In this context, the automatic deployment of applications emerges as a practically indispensable requirement to ensure the high availability demanded by the current scenario. Manual processes of dependency installation and service execution are obsolete practices that belong to the past. This challenge is being enthusiastically taken up by several organizations seeking not only to remain competitive, but also to adopt best practices and focus on business strategies that benefit both the processes and the people who depend on them.
In this context of transformation, we highlight the key relevance of dockerization, using readme as a basis for this process. In addition, the implementation of Continuous Delivery (CI/CD) practices, supported by services such as AWS CodePipeline, stands as a cornerstone to accelerate and optimize development cycles, providing a continuous and reliable flow from code writing to production deployment. These strategies not only drive operational efficiency, but also lay the foundation for agile, future-oriented innovation in a constantly evolving technology environment.
About the customer
It is a company that provides professional virtual services for the legal world, where through its developments it helps its clients to more efficiently manage their legal matters, such as collaborative work, document signing, process traceability. Their clients are law firms and independent lawyers and companies that want to keep track of certifications, regulations, and legal processes through the use of technology.
Number of employees: 11-50
Age: 8 years
Customer Challenge
Phase 1: customer request
3HTP Cloud Services’ proposal for LEGOPS focuses on providing Specialized Technical Consulting and Support to optimize the architecture and operation model of its systems in AWS. In the initial phase, we address the review and improvement of the existing architecture, the implementation of environments and the empowerment of DevOps processes, including the creation of automation pipelines. This project is presented as a comprehensive commitment to elevate the operational efficiency and performance of LEGOPS, providing customized and certified solutions by DevOps and AWS experts.
Phase 2: proof of concept
A first phase of the project with LEGOPS, which should be considered for the context that will be explained later, is the phase in which the applications were dockerized. Here LEGOPS (hereinafter the client) showed the readme (informative document that indicates the necessary commands for the deployment and additional information) with which they deployed the applications and installed the necessary dependencies for the operation is these. In AWS but this was completely manual.
Here the Dockerfile files were built, containerization tests were performed exposing the applications locally and deployed in an AWS environment with the minimum requirements, which was preceded by the provisioning of an infrastructure in the cloud provider Amazon Web Service (AWS), where application container services, automated pipelines for change management at the development and deployment level (DevOps lifecycle), databases in the RDS service, compute capacity supported in the EC2 service and an EKS (Elastic Kubernetes Services) cluster for application management and scaling were implemented; a positive result was obtained from the initial requirements set forth by the LEGOPS client.
Phase 3: deployment in controlled environments
In phase 2, according to the success of the first phase, the opportunity arose to replicate what was done in that first phase in three different accounts (development, testing and production), which were done in a progressive and controlled manner that allowed fine- tuning the performance parameters in terms of computation, networks, security, database consumption and application availability. In addition, stress and performance tests were performed on the applications. The greatest gain of phase two was the knowledge generated that was delivered to the client and the capacity acquired by the 3HTP architects’ team.
Phase 4: production start-up
The last phase consisted of making available what was done in the 3 accounts, in a productive account to automate the life cycle of the 9 applications that the client has. Here the observations of the 3 controlled accounts were considered, a synchronization was made between Github and Codecommit for the versioning of the repositories, as additional measures CPS policies were created in Cloudfront, cookies optimization, JS libraries update and performance details that made more efficient the consumption of the applications.
Partner Solution
3HTP focused activities
The Customer, in collaboration with its teams of architects, administrators and developers, recognized in AWS a strategic partner to automate the deployment of its web applications.
In the context of this project, 3HTP Cloud Services played an active role in providing guidance, establishing key definitions and implementing technical solutions both in infrastructure and in supporting the development and automation teams.
3HTP Cloud Services’ participation focused on the following areas:
Validation of the architecture proposed by the client.
Deployment of infrastructure-as-code (IaC) projects on AWS.
Implementation of automated processes and continuous integration/deployment (CI/CD) for infrastructure and microservices management.
Execution of stress and load tests in the AWS environment.
This strategic and multi-faceted involvement of 3HTP Cloud Services contributed significantly to building a robust, efficient infrastructure aligned with AWS standards of excellence, thus supporting the overall success of the project.
Services Offered by 3HTP Cloud Services:
The organization already had an initial cloud adoption structure for its customer portal. Therefore, as a multidisciplinary team, we proceeded with an analysis of the present situation and the proposal made by the client. The following relevant suggestions for the architecture were derived from this comprehensive assessment:
Differentiation of architectures for productive and non-productive environments.
Use of Infrastructure as Code to generate dynamic environments, segmented by projects, business units, among others.
Implementation of Continuous Integration/Continuous Delivery (CI/CD) practices to automate the creation, management, and deployment of both infrastructure and microservices.
Architecture
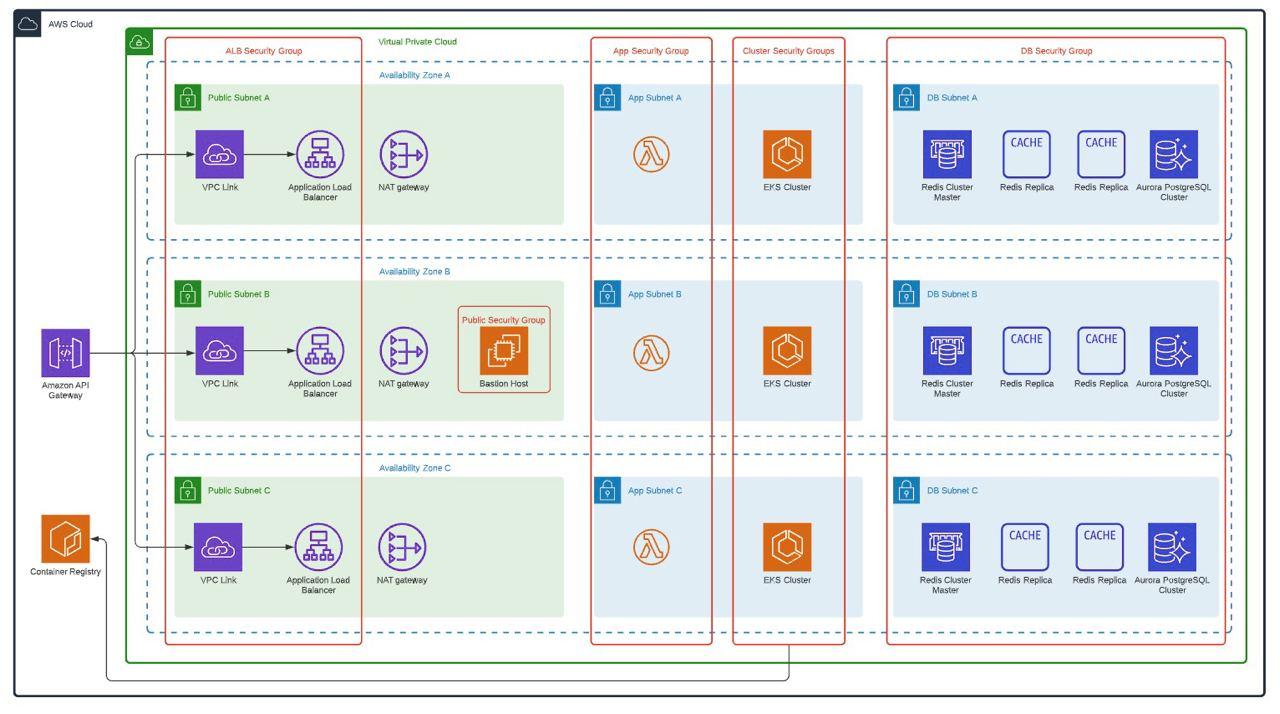
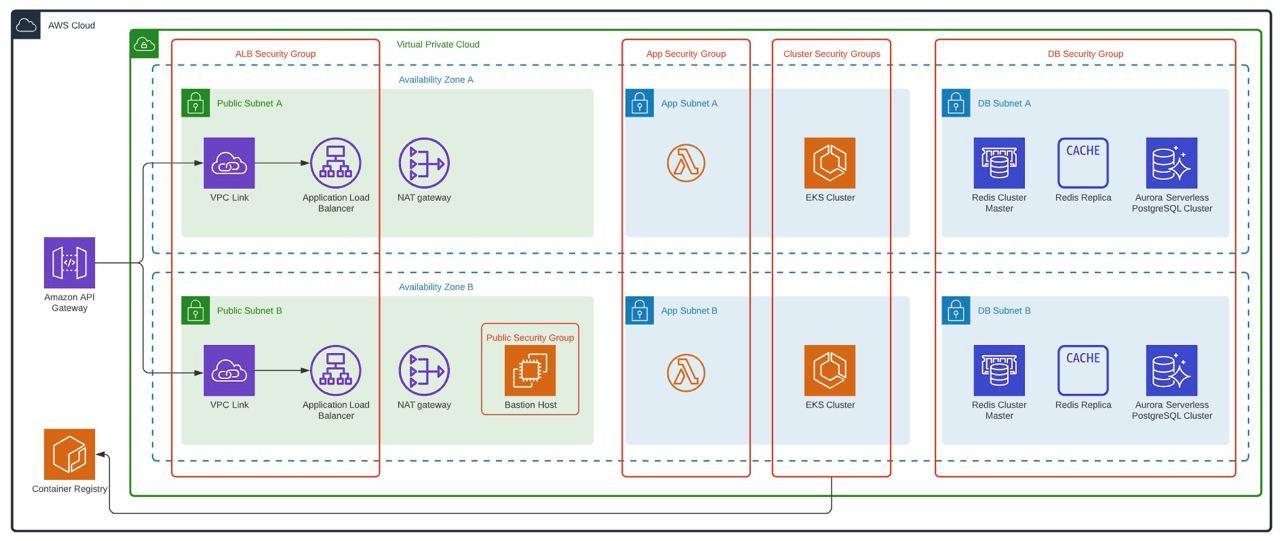
To replicate what was done in phase 1, the following architecture was proposed with all the immersed services used, which was received and approved by the client. This also has the best practices of AWS Well Architected where security, performance efficiency, operational excellence, reliability, cost optimization and sustainable architecture are protagonists.
Several services work together to support applications and data. Key services include Amazon S3 for secure file storage, Amazon CloudWatch for monitoring, and AWS IAM for access control. In addition, we use Amazon SQS for scalable and reliable message queuing between distributed application components. This facilitates asynchronous communication and improves overall system resiliency. In addition, SSL/TLS certificates were easily managed with AWS Certificate Manager, ensuring secure connections for applications and data.
The Virginia region hosts an ECR as a container image repository, which made it possible to efficiently manage and store Docker images for containerized applications. DevOps services such as AWS CodePipeline, CodeBuild, CodeCommit and CodeDeploy automate these software release processes, optimizing the deployment pipeline. AWS CloudFront serves as a content delivery network, optimizing content delivery to end users and is protected by AWS Web Application Firewall to defend against web-based attacks.
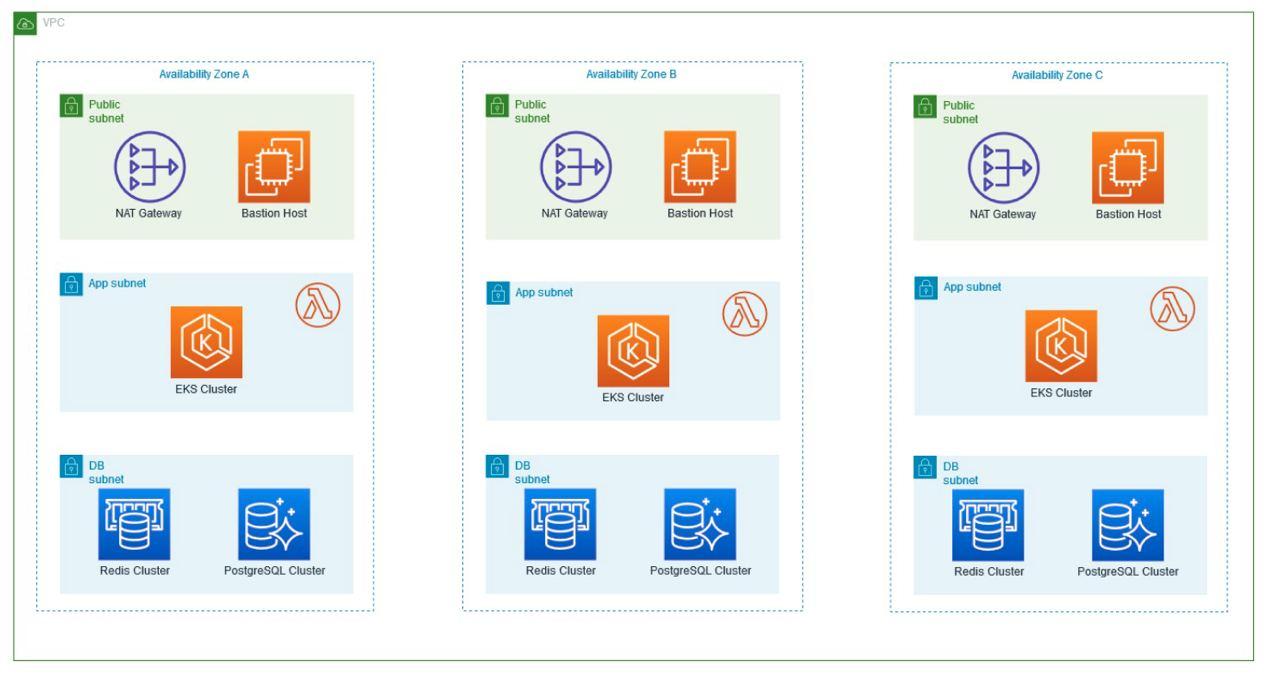
Within the Virtual Private Cloud (VPC) created, which spans two Availability Zones, there is an Internet gateway, a public subnet with an Application Load Balancer, and a secure EC2 instance known as “Bastion” for additional protection. Traffic is routed from the public subnet to the private subnets through a NAT Gateway. One private subnet hosts an Amazon RDS instance for database management and an OpenSearch service for search functionality. In addition, the second private subnet includes an EKS service, responsible for managing containerized applications, along with an auto-scaling EC2 worker node. All services within the VPC are protected by their respective security groups and interconnected via routing tables.
Used services
AWS Certificate Manager: ACM is a service that makes it easy for users to provision, manage and deploy SSL/TLS certificates for use with AWS services. It provides a simple way to secure network communications and encrypt data transmitted between clients and servers.
S3 (Simple Storage Service): S3 is a highly scalable and secure cloud storage service that allows users to store and retrieve data, such as files, documents, images, and videos, from anywhere at any time.
Amazon CloudWatch: CloudWatch is a monitoring and management service that provides real-time insights into the operational health of your AWS resources, helping you monitor metrics, collect, and analyze historical archives, and set alarm clocks.
AWS IAM (Identity and Access Management): IAM is a service that allows you to securely manage user access and permissions to AWS resources, allowing you to control who can access what is in your AWS environment.
Amazon SQS (Simple Queue Service): a fully managed message queuing service that enables decoupling and scaling of microservices, serverless applications and distributed systems, provides a reliable and scalable platform for sending, storing and receiving messages between software components, ensuring smooth and efficient communication.
ECR (Elastic Container Registry): ECR is a fully managed container image registry that simplifies the storage, management, and deployment of container images, providing a secure and scalable solution.
AWS CodePipeline: CodePipeline is a continuous integration and continuous delivery (CI/CD) service that automates your software release processes, allowing you to build, test and deploy your applications from trusted sources.
AWS CodeDeploy: CodeDeploy is a fully managed deployment service that automates application deployments to EC2 instances, on-premises instances and serverless Lambda functions, ensuring fast and reliable application updates.
AWS CodeBuild: CodeBuild is a fully managed build service that compiles source code, runs tests, and produces software packages, eliminating the need to maintain your build infrastructure.
CodeCommit: CodeCommit is a fully managed source control service that hosts secure and scalable Git repositories, allowing you to store and manage your code well.
AWS CloudFront CDN: is a global content delivery network (CDN) that accelerates the delivery of web content to end users around the world with low latency and high transfer speeds.
AWS Web Application Firewall: WAF is an AWS service that connects to AWS Cloudfront, helps protect your web applications from common web exploits and attacks. It allows you to define rules to filter and monitor HTTP and HTTPS requests to applications.
VPC (Virtual Private Cloud): VPC is a virtual network environment that allows you to create a private, isolated section of the AWS cloud, giving you control over your virtual network and allowing you to define IP ranges, subnets and network gateways.
Availability Zones (AZ): Availability Zones are isolated locations within an AWS region that provide fault tolerance and high availability. They are interconnected with low latency links to support resiliency and redundancy.
Internet Gateway: Internet Gateway is a horizontally scalable gateway that enables communication between your VPC and the Internet, allowing you to access resources in your VPC from the Internet and vice versa.
Routing tables: Routing tables are rules that govern network traffic within a VPC, allowing you to manage the flow of data between subnets and control connectivity to the Internet and other resources.
EC2 (Elastic Compute Cloud): EC2 provides scalable virtual servers in the cloud, known as EC2 instances. It allows you to quickly launch and manage virtual machines with various configurations, providing flexible and resizable compute capacity for your applications.
Application Load Balancing: ALB is an AWS load balancing service that evenly distributes incoming application traffic across multiple destinations, improving scalability, availability, and responsiveness. It supports advanced features such as content-based routing and SSL/TLS termination.
AWS OpenSearchService: AWS OpenSearch is a fully managed, highly scalable, open-source search service based on the Apache OpenSearch project. It simplifies the deployment and management of search functionality within your applications.
RDS (Relational Database Service): RDS is a fully managed relational database service that simplifies the configuration, operation and scaling of relational databases. It supports popular database engines and provides automated backups, patching and high availability for reliable and scalable data storage.
EKS (Elastic Kubernetes Service): EKS is a managed Kubernetes service that simplifies the deployment and scaling of containerized applications. It automates the management of the underlying Kubernetes infrastructure, allowing you to focus on developing and running your applications efficiently.
Security Groups: Acting as virtual firewalls, security groups provide granular access control for instances by defining authorized protocols, ports and IP ranges, ensuring secure inbound and outbound traffic.
Infrastructure as code
A significant advantage of this technology refresh and paradigm shift lies in the adoption of Infrastructure as Code (IaC). Previously, our client was manually managing its entire infrastructure through the AWS console and command line interface (CLI), which presented considerable challenges in terms of scalability and operational agility.
Manual management became increasingly complex as the infrastructure grew, as upgrades and modifications required manual interventions that slowed down the process. Implementing Terraform was a significant change, allowing us to create a project where, through code, planning, building and destroying infrastructure in the AWS cloud became as simple as a click, giving precise control over every action.
With Terraform, we have achieved more efficient and agile infrastructure management, overcoming the limitations of manual administration. This code-based approach not only improves speed and consistency in resource deployment, but also provides greater flexibility to adapt to changes in scale and the demands of the evolving technology environment. In summary, the adoption of IaC, through Terraform, has enabled our client to optimize their infrastructure on AWS in an effective and simplified manner.
Terraform
Terraform is an IaC (Infrastructure as Code) technology that allows us to define and maintain through configuration files using HCL (Hashicorp Configuration Language, a domain-specific language developed by them) all our infrastructure deployed through different cloud providers (AWS, Azure, GCP, etc). Also in on-premise installations, as long as we expose an API through which Terraform can communicate.
Code commit and Github
In our ongoing commitment to adapt to the specific needs of our clients, we implemented a synchronization process between GitHub and CodeCommit. Recognizing the importance of flexibility and efficient collaboration in software development, this strategic integration allowed our client to take advantage of the best of both platforms.
GitHub, known for its robust community and collaborative tools, integrated with CodeCommit, the AWS version control service, to streamline repository management and facilitate collaboration across distributed teams. This hybrid approach not only improved workflow efficiency, but also ensured greater security and compliance with industry standards.
By implementing this synchronization between GitHub and CodeCommit, our client experienced improved synergy in software development, allowing for agile collaboration and accurate version tracking. As such, the client was able to continue their workflow as normal while changes were reflected in AWS Codecommit.
Dockerization of applications
Docker, a cornerstone of modern application management, represents an open-source platform that simplifies application containerization. By encapsulating applications and their dependencies in lightweight, self-contained containers, Docker provides a standardized solution for efficiently packaging, distributing, and running software. Containerization allows applications to operate in a consistent and isolated environment, ensuring reliability from development to production. Docker stands out for its ability to simplify deployment, improve scalability, and optimize application management, making it an essential tool for development and operations teams.
Application containerization using DockerFiles represents a crucial step towards portability and consistency in software development. By using DockerFiles, the application’s runtime environment is described, facilitating its uniform deployment across multiple environments, including development, test and production. This approach provides a solid foundation to ensure that applications run reliably, regardless of differences between environments. Containerization with DockerFiles not only simplifies dependency management, but also streamlines the development cycle by eliminating concerns related to environment variations.
How did we do it?
In response to the need to optimize the deployment of our client’s web applications, we undertook a significant transformation through the containerization of their applications. Initially, we observed that the manual deployment process, which involved the installation of dependencies through specific commands, resulted in a considerable investment of time and effort.
To address this issue, we dove into the existing README files of the applications, taking advantage of the detailed information provided there. We implemented a containerization process that encapsulates each application in separate Docker containers. This approach allowed our client to eliminate the tedious manual tasks associated with installing dependencies and configuring the environment, significantly simplifying the deployment process.
Containerization not only accelerated deployment, but also brought an additional level of consistency and portability to the applications. Now, with container images ready for deployment, our customer can deploy new versions and upgrades more quickly and confidently, reducing the risk of errors associated with manual methods.
We are pleased to have delivered a solution that not only improves operational efficiency, but also lays the foundation for a more agile and scalable deployment in the future. Containerization has proven to be a key strategy for modernizing and optimizing development and deployment workflows, putting our client in a stronger position to meet the dynamic challenges of today’s technology environment.
Environment configuration files
Environment configuration files complemented the Dockerfiles containerization, adding a crucial layer of flexibility. These files contain environment variables and settings specific to each environment, such as development, test, or production. By separating the configuration from the source code, Environment configuration files enabled easy adaptation of the application to different contexts without requiring modifications to the source code. This not only improves the portability of the application, but also ensures a flexible and secure configuration that can be managed independently throughout the development and deployment lifecycles.
Publication of Docker images in ECR
After having the applications containerized, and images ready they were published to the Amazon Elastic Container Registry (ECR) and is an essential part of the lifecycle of containerized applications. This process involved storing and managing Docker container images in a highly scalable and secure repository. Opting for ECR ensured the availability of the images.
ECR not only acted as a centralized repository for images, but also provided secure access control and retention policies, ensuring integrity and efficiency in image lifecycle management. In addition, its native integration with other AWS services simplified the implementation and ongoing deployment of applications, allowing client development teams to focus on innovation and development, without worrying about the logistical management of images.
This approach not only addresses security and availability, but also improves image version traceability, crucial for maintaining consistency and integrity in development and production environments.
AWS EKS Configurations
In the process of deploying containerized applications, hosted in the AWS Elastic Container Registry (ECR), we play a crucial role in creating thorough Kubernetes manifests and services to orchestrate the execution of these containers. Kubernetes manifests represent the very essence of application orchestration in containerized environments.
These YAML files serve as detailed documents that describe and define the configuration and resources required to deploy applications on a Kubernetes cluster. By addressing crucial elements such as deployments and services, Kubernetes manifests provide comprehensive guidance for Kubernetes to efficiently orchestrate and manage applications.
In particular, the creation of deployments is a fundamental part of this process. Deployments in Kubernetes allow us to define and declare the desired state of applications, managing the creation and update of the corresponding pods. This feature is essential to ensure the availability and scalability of our containerized applications.
In addition, exposing services is another crucial aspect. By creating services in Kubernetes manifests, we establish an abstraction layer that facilitates communication between different components of client applications. This allows external or internal users to access applications in a controlled and secure manner.
The declarative nature of manifests means that developers can define the desired state of their applications, allowing Kubernetes to interpret and act accordingly. These files not only make deployment easier, but also ensure consistency in application management, regardless of the complexity and scale of the cluster.
By leveraging Kubernetes manifests, teams can ensure efficient management and seamless deployment of applications in container-based environments. This consolidates operations and simplifies application lifecycle management, bringing greater reliability and stability to the automated deployment ecosystem.
Automatic CI/CD deployment
CodePipeline Deployment
We set up an end-to-end workflow using AWS development and deployment tools, specifically AWS CodePipeline, AWS CodeBuild and AWS CodeDeploy. This integration enables seamless continuous delivery (CI/CD), allowing us to deliver fast and secure updates to your application.
Continuous Integration and Continuous Delivery (CI/CD) pipelines represent an essential framework for efficient automation of the entire application development and deployment process. Designed to optimize code quality and delivery speed, these pipelines provide a complete solution from change integration to continuous deployment in test and production environments.
Continuous Integration (CI)
CI pipelines automatically initiate testing and verification as soon as changes are made to the source code. This ensures that any modifications are seamlessly integrated with existing code, identifying potential problems early and ensuring consistency in collaborative development.
Continuous Delivery (CD)
The Continuous Delivery phase involves automating deployment in test and production environments. CD pipelines enable fast and secure delivery of new application releases, reducing cycle times and improving deployment efficiency.
AWS CodeBuild: We configure custom build environments that match the specific requirements of your web applications. Builds are automatically triggered when there are changes to the repository, ensuring consistency and availability of deployment artifacts.
AWS CodeDeploy: We implemented a deployment group that ensures a smooth and gradual deployment. Monitoring policies were configured to automatically revert the deployment in case problems are detected.
AWS CodePipeline: We have created a customized pipeline that mirrors your development process, from source code retrieval to production deployment. The pipeline consists of several stages, including source code retrieval from your repository, building the application with AWS CodeBuild, and automated deployment using CodeDeploy.
Result and Benefits
Rapid Continuous Delivery: With full automation, updates are deployed faster, improving delivery time for new features and bug fixes.
Greater Confidence: Gradual implementation and automatic rollback policies ensure greater confidence in the stability of new versions.
Visibility and Monitoring: Detailed monitoring dashboards were implemented to provide a complete view of the implementation process, making it easier to identify and correct problems.
Refinement and definitions of standards to be used in the infrastructure.
Cloud Front
As a cloud services company, we provisioned Amazon CloudFront on AWS for our client, a solution that optimizes the delivery of web content quickly and securely. In addition, we implemented Crucial Preloaded Security (CPS) and HTTP Strict Transport Security (HSTS) policies to strengthen the security and reliability of the system.
CPS policies ensure greater protection by establishing predefined rules to mitigate known threats, thus guaranteeing a more attack-resistant environment. On the other hand, the implementation of HSTS adds an additional layer of security by forcing exclusive communication over HTTPS, preventing possible attacks such as downgrading to HTTP. These measures not only optimize content delivery, but also reinforce security, meeting the highest standards in data protection and user experience.
AWS SQS
As a leading cloud services company, we successfully implemented Amazon Simple Queue Service (SQS) to optimize our client’s application architecture. SQS, a managed messaging service, has allowed us to decouple and scale critical components, improving the efficiency and reliability of their systems.
By adopting SQS, we apply the “First In, First Out” (FIFO) principle to ensure sequential processing of messages in the order in which they were placed in the queue. This is crucial in applications where sequentiality and time synchronization are essential, such as in order systems and transaction processing, in this specific case for customer applications such as electronic signature of documents and traceability of legal matters.
Nginx-Ingress-Controller
We have successfully integrated NGINX into our client’s architecture, empowering their web applications with a robust, multi-functional server. NGINX not only excels as an open source web server, but also plays essential roles as a reverse proxy, load balancer and cache server. Its efficient architecture improves both the performance and security of web applications, making it the ideal choice for handling large volumes of concurrent connections.
In addition, we have implemented the NGINX-specific Ingress Controller as an integral part of Kubernetes environments. This component manages HTTP and HTTPS traffic rules, using NGINX to direct traffic to services deployed in the cluster. By configuring Ingress rules, such as routes and redirects, the Ingress Controller optimizes the efficient exposure and management of web services. The specific implementation of NGINX enhances security and efficiency, offering a complete solution for the controlled exposure of web services, thus contributing to the construction of modern and scalable architectures in container-based environments.
Stress and load testing for AWS implementation
We conducted extensive testing on our client’s applications to ensure optimal performance in a variety of situations. These tests included:
Stress Testing: Focused on evaluating how applications handle extreme situations or sudden load peaks. Conditions that exceed normal operating limits are simulated to identify potential failure points and ensure stability under stress.
Load Tests: Designed to evaluate the behavior of applications under sustained and significant loads. These tests seek to determine the capacity of applications to handle constant demand, identifying possible bottlenecks and optimizing resources for continuous performance.
Performance Testing: Focused on measuring the speed and efficiency of applications under normal conditions. System response to various operations is evaluated to ensure fast loading times and a smooth user experience.
These tests allowed us to identify areas for improvement, optimize resources and ensure that applications perform reliably under various circumstances. Our dedication to comprehensive testing reflects our commitment to delivering technology solutions that are not only robust but also highly efficient and capable of adapting to the changing demands of the environment.
Benefits obtained by the customer
The adoption of advanced containerization and orchestration solutions has significantly transformed the technology landscape for our client. After dockerizing their applications and leveraging key services such as Kubernetes on Amazon EKS, automated deployment with AWS Pipelines, and strategic implementation of services such as CloudFront, SQS, along with robust security measures and a distributed VPC infrastructure across multiple availability zones, our client has experienced several notable benefits.
Scalability and Efficiency: Containerization with Docker and orchestration using Kubernetes in EKS has allowed our client to scale their applications efficiently, dynamically adapting to changing traffic demands without compromising performance.
Continuous and Automated Deployment: The implementation of AWS Pipelines has facilitated continuous and automated deployment, streamlining the development lifecycle and enabling fast and secure delivery of new features and updates to applications.
Performance Optimization: The use of CloudFront has significantly improved the delivery of web content, reducing load times and providing a faster and more efficient user experience across the board.
Efficient Message Handling: SQS has optimized message handling, enabling seamless communication between different application components, ensuring reliability and consistency in data processing.
Robust Security: The implementation of advanced security measures, within a well- structured VPC distributed across multiple availability zones, has strengthened data protection and application integrity against potential threats.
High Availability and Fault Tolerance: The distribution of the infrastructure in several availability zones has improved availability and fault tolerance, ensuring service continuity even in adverse situations.
Together, these solutions have enabled our client not only to improve operational efficiency and security, but also to offer an enhanced and scalable user experience, consolidating its position in a constantly evolving technological environment.
Conclusions
In conclusion, the road to a successful technological upgrade proves to be a fundamental journey for modern organizations. Beyond mere aspiration, it requires a solid commitment and a strategic vision that allows the implementation of truly fruitful improvements. In this context, the automatic deployment of applications is an indispensable component to ensure the high availability demanded by today’s dynamic landscape.
Abandoning obsolete practices and embracing dockerization, using readme as a guide, has emerged as a fundamental step in this evolution. In addition, the adoption of Continuous Delivery (CI/CD) practices, supported by innovative services such as AWS CodePipeline, emerges as a cornerstone to accelerate and optimize development cycles. This approach not only drives operational efficiency, but also lays the foundation for agile, future-oriented innovation in a constantly evolving technology environment.
By highlighting the relevance of strategies such as dockerization and CI/CD implementation, these organizations not only seek to remain competitive, but also to adopt best practices. Thus, they are orienting their efforts towards business strategies that not only benefit internal processes, but also the people who depend on them. In this context of transformation, technological evolution is not only a requirement, but an opportunity for growth and excellence in the delivery of advanced technological solutions.
About Us
A professional services company with regional coverage with a presence in Chile, Colombia, Peru and the USA. It is exclusively oriented to cover all business needs and technology organizations, in the areas of Infrastructure Management (Middleware), Development of Cloud Technologies (Cloud) and Software Life Cycle Automation and Implementation Processes (DevOps). Our operational strategy is oriented to meet the needs of our clients in the areas involved on three fundamental pillar of technology.
Case: Evolving User Experience – A Three-Phase Banking Solution
Introduction: The unprecedented impact of COVID-19 on several financial institutions reshaped user habits almost overnight. During lockdown, the surge in online banking showcased the unpreparedness of many portals to handle heavy workloads. While some lagged in adapting, others, like our client, a renowned Chilean financial institution with over 50 years of service and over a million users, swiftly began their digital transformation journey.
Phase 1: The Pandemic Response
During the peak of the pandemic, our client embarked on its initial digital transformation. They adopted the cloud to ensure their platforms remained stable, scalable, and secure. Consequently, they were able to introduce new functionalities, enabling users to execute tasks previously limited to physical branches. For this massive endeavor, they employed the Amazon Web Services (AWS) Cloud platform, paired with the expert guidance of a team of specialized professionals.
Phase 2: Post-Pandemic Enhancements
Post-pandemic, as users and businesses acclimated to online operations, our client entered the second phase of their transformation. This involved enhancing their architecture. Their first order of business was load testing to understand how concurrent online activity impacted their on-premises components. This was crucial in determining optimal configurations for AWS EKS and AWS API Gateway services.
Furthermore, as the business expanded its online offerings, new services were integrated. Security became paramount, prompting the institution to implement stricter validations and multi-factor authentication (MFA) for all users. Phase 3: Continuous Improvements and Expansion
With more users adapting to online banking, the third phase saw the introduction of additional applications, enhancing the suite of services offered. The architecture was continuously revised and updated to cater to the ever-increasing demands of online banking.
Security was further tightened, and robust monitoring and traceability features were incorporated, providing deeper insights and ensuring system stability.
Projects Realized
The Client, together with its Architecture, Development, Security, and Infrastructure areas, saw in AWS an ally to carry out the construction of a new Portal, taking advantage of Cloud advantages such as elasticity, high availability, connectivity and cost management.
The project conceived contemplated the implementation of a frontend (Web and Mobile) together with a layer of micro-services with integration towards its On-Premise systems via consumption of services exposed in its ESB that in turn accesses its legacy systems, thus forming an architecture hybrid.
Within the framework of this project, 3HTP Cloud Services actively participated in the advice, definitions, and technical implementations of the infrastructure and support to the development and automation teams, taking as reference the 05 pillars of the AWS well-architected framework.
3HTP Cloud Services participation focused on the following activities:
Validation of architecture proposed by the client
Infrastructure as code (IaC) project provisioning on AWS
Automation and CI / CD Integration for infrastructure and micro-services
Refinement of infrastructure, definitions, and standards for Operation and monitoring
Stress and Load Testing for AWS and On-Premise Infrastructure
Outstanding Benefits Achieved
Our client’s three-phase approach to digital transformation wasn’t just an operational shift; it was a strategic masterstroke that propelled them to the forefront of financial digital innovation. Their benefits, both tangible and intangible, are monumental. Here are the towering achievements:
Unprecedented Automation & Deployment: By harnessing cutting-edge tools and methodologies, the client revolutionized the automation, management, and deployment of both their infrastructure and application components. This turbocharged their solution’s life cycle, elevating it to industry-leading standards.
Instantaneous Environment Creation: The ingeniousness of their automation prowess enabled the generation of volatile environments instantaneously, showcasing their technical agility and robustness.
Robustness Redefined: Their infrastructure didn’t just improve; it transformed into an impregnable fortress. Capable of handling colossal load requirements, both in productive and non-productive arenas, meticulous dimensioning was executed based on comprehensive load and stress tests. This was consistently observed across AWS and on-premises, creating a harmonious hybrid system synergy.
Dramatic Cost Optimization: It wasn’t just about saving money; it was about smart investing. Through astute utilization of AWS services, like AWS Spot-Aurora Server-less, they optimized costs without compromising on performance. These choices, driven by findings and best practices, epitomized financial prudence.
Achievement of Exemplary Goals: The institution’s objectives weren’t just met; they were exceeded with distinction. Governance, security, scalability, continuous delivery, and continuous deployment (CI/CD) were seamlessly intertwined with their on-premises infrastructure via AWS. The result? A gold standard in banking infrastructure and operations.
Skyrocketed Technical Acumen: The client’s teams didn’t just grow; they evolved. Their exposure to the solution’s life cycle made them savants in their domains, setting new benchmarks for technical excellence in the industry.
Services Performed by 3HTP Cloud Services: Initial Architecture Validation
The institution already had a first adoption architecture in the cloud for its client portal, therefore, as a multidisciplinary team, we began with a diagnosis of the current situation and the proposal made by the client; From this diagnosis and evaluation, the following recommendations relevant to architecture were obtained:
Separation of architectures for productive and non-productive environments
The use Infrastructure as code in order to create volatile environments, by projects, by business unit, etc.
CI / CD implementation to automate the creation, management, and deployment of both Infrastructure and micro-services.
Productive Environment Architecture
This architecture is based on the use of three Availability Zones (AZ), additionally, On-Demand instances are used for AWS EKS Workers and the use of reserved instances for database and cache with 24×7 high availability.
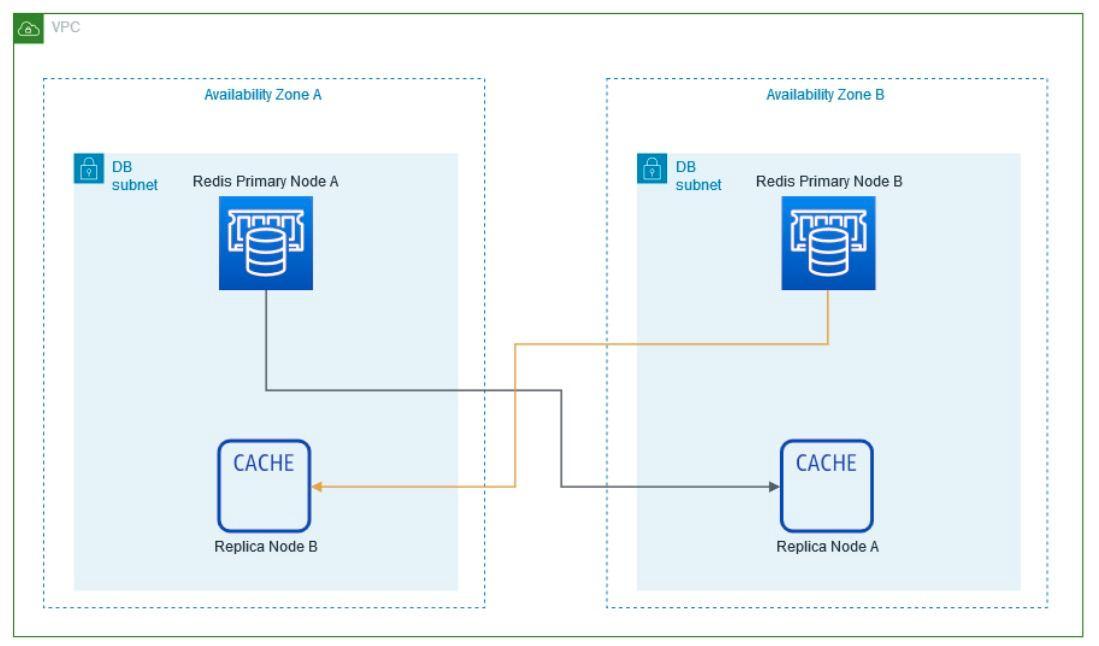
The number of instances to use for the Redis Cluster is defined.
Productive Diagram
Non-Productive Environment Architecture
Considering that non-production environments do not require 24/7 use, but if it is necessary that they have at least an architecture similar to that of production, an approved architecture was defined, which allows the different components to be executed in high availability and at the same time allows minimize costs. For this, the following was defined:
Reduction of availability zones for non-productive environments, remaining in two availability zones (AZ)
Using Spot Instances to Minimize AWS EKS Worker Costs
Configuration of off and on of resources for use during business hours.
Using Aurora Serverless
The instances to be used are defined considering that there are only two availability zones, the number of instances for Non-Production environments is simply 4.
Non-production environments diagram
Infrastructure as Code
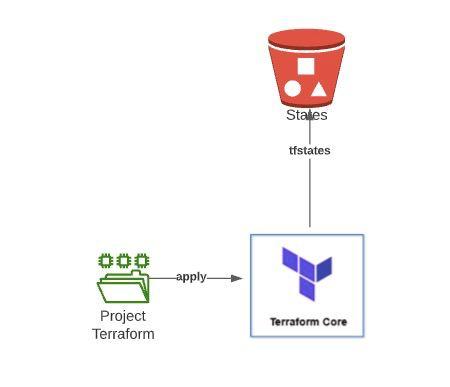
In order to achieve the creation of the architectures in a dynamic way additionally that the environments could be volatile in time, it was defined that the infrastructure must be created by means of code. For this, Terraform was defined as the primary tool to achieve this objective.
As a result of this point, 2 totally variable Terraform projects were created which are capable of creating the architectures shown in the previous point in a matter of minutes, each execution of these projects requires the use of a Bucket S3 to be able to store the states created by Terraform.
Additionally, these projects are executed from Jenkins Pipelines, so the creation of a new environment is completely automated.
Automation and CI / CD Integration for infrastructure and micro-services
Micro-services Deployment in EKS
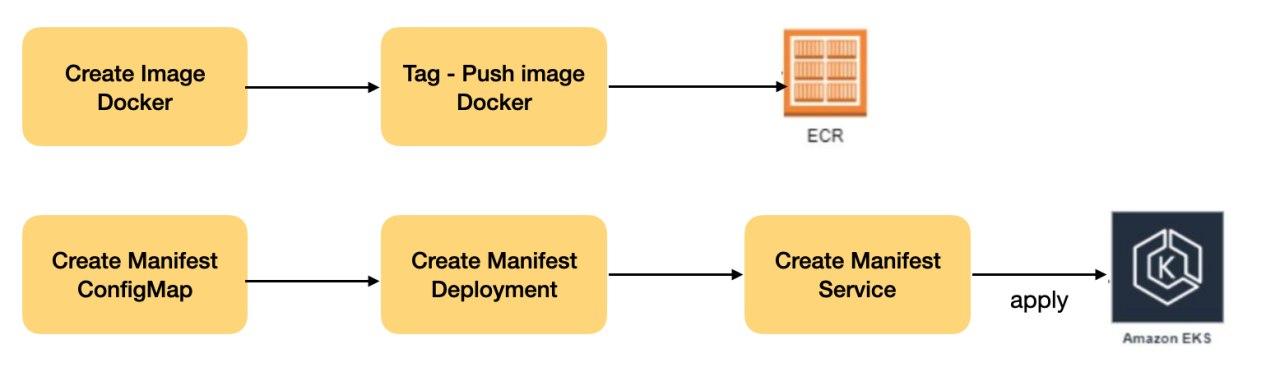
We helped the financial institution to deploy the micro-services associated with its business solution in the Kubernetes Cluster (AWS EKS), for this, several definitions were made in order to be able to carry out the deployment of these micro-services in an automated way, thus complying with the process Complete DevOps (CI and CD).
Deployment Pipeline
A Jenkins pipeline was created to automatically deploy the micro-services to the EKS cluster.
Tasks executed by the pipeline:
In summary the steps of the pipeline:
Get micro-service code from Bitbucket
Compile code
Create a new image with the package generated in the compilation
Push image to AWS ECR
Create Kubernetes manifests
Apply manifests in EKS
Refinement and definitions and standards to be used on the infrastructure
Image Hardening
For the institution and as for any company, security is critical, for this, an exclusive Docker image was created, which did not have known vulnerabilities or allow the elevation of privileges by applications, this image is used as a basis for micro-services, For this process, the Institution’s Security Area carried out concurrent PenTest until the image did not report known vulnerabilities until then.
AWS EKS configurations
In order to be able to use the EKS clusters more productively, additional configurations were made on it:
Use of Kyverno: Tool that allows us to create various policies in the cluster to carry out security compliance and good practices on the cluster (https://kyverno.io/)
Metrics Server installation: This component is installed in order to be able to work with Horizontal Pod Autoscaler in the micro-services later
X-Ray: The use of X-Ray on the cluster is enabled in order to have better tracking of the use of micro-services
Cluster Autoscaler: This component is configured in order to have elastic and dynamic scaling over the cluster.
AWS App Mesh: A proof of concept of the AWS App Mesh service is carried out, using some specific micro-services for this test.
Defining Kubernetes Objects
In Deployment:
Use of Resources Limit: in order to avoid overflows in the cluster, the first rule to be fulfilled by a micro-service is the definition of the use of memory and CPU resources both for the start of the Pod and the definition of its maximum growth. Client micro-services were categorized according to their use (Low, Medium, High) and each category has default values for these parameters.
Use of Readiness Probe: It is necessary to avoid loss of service during the deployment of new versions of micro-services, that is why before receiving a load in the cluster they need to perform a test of the micro-service.
Use of Liveness Probe: Each micro-service to be deployed must have a life test configured that allows checking the behavior of the micro-service
Services
The use of 2 types of Kubernetes Services was defined:
ClusterIP: For all micro-services that only use communication with other micro-services within the cluster and do not expose APIs to external clients or users.
NodePort: To be used by services that expose APIs to external clients or users, these services are later exposed via a Network Load Balancer and API Gateway.
ConfigMap / Secrets
Micro-services should bring their customizable settings in Kubernetes secret or configuration files.
Horizontal Pod Autoscaler (HPA)
Each micro-service that needs to be deployed in the EKS cluster requires the use of HPA in order to define the minimum and maximum number of replicas required of it.
The client’s micro-services were categorized according to their use (Low, Medium, High) and each category has a default value of replicas to use.
Stress and Load Testing for AWS and On-Premise Infrastructure
One of the great challenges of this type of architecture (Hybrid) where the backend and core of the business are On-Premise and the Frontend and logic layers are in dynamic elastic clouds, is to define to what extent architecture can be elastic without affecting the On-Premise and legacy services related to the solution.
To solve this challenge, load and stress tests were carried out on the environment, simulating peak business loads and normal loads, this, monitoring was carried out in the different layers related to the complete solution at the AWS level (CloudFront, API Gateway, NLB, EKS, Redis, RDS) at the on-premise ESB, Legacy, Networks and Links level.
As a result of the various tests carried out, it was possible to define the minimum and maximum elasticity limits in AWS, (N ° Worker, N ° Replicas, N ° Instances, Types of Instances, among others), at the On-Premise level (N ° Worker, Bandwidth, etc).
Conclusion
Navigating the labyrinth of hybrid solutions requires more than just technical know-how; it mandates a visionary strategy, a well-defined roadmap, and a commitment to iterative validation.
Our client’s success story underscores the paramount importance of careful planning complemented by consistent execution. A roadmap, while serving as a guiding light, ensures that the course is clear, milestones are defined, and potential challenges are anticipated. But, as with all plans, it’s only as good as its execution. The client’s commitment to stick to the roadmap, while allowing flexibility for real-time adjustments, was a testament to their strategic acumen.
However, sticking to the roadmap isn’t just about meeting technical specifications or ensuring the system performs under duress. In today’s dynamic digital era, users’ interactions with applications are continually evolving. With each new feature introduced and every change in user behavior, the equilibrium of a hybrid system is tested. Our client understood that the stability of such a system doesn’t just rely on its technical backbone but also on the real-world dynamic brought in by its users.
Continuous validation became their mantra. It wasn’t enough to assess the system’s performance in isolation. Instead, they constantly gauged how new features and shifting user patterns influenced the overall health of the hybrid solution. This holistic approach ensured that they didn’t just create a robust technical solution, but a responsive and resilient ecosystem that truly understood and adapted to its users.
In essence, our client’s journey offers valuable insights: A well-charted roadmap, when paired with continuous validation, can drive hybrid solutions to unprecedented heights, accommodating both the technological and human facets of the digital landscape.
PROJECT REFERENCE Identity Validator System – Pension Fund Administrator
The Pension Fund Administrator of Colombia is part of a well-known Colombian holding company and is one of the largest administrators of pension and census funds in the country with more than 1.6 million members. This pension fund manager manages three types of funds: unemployment insurance, voluntary pensions, and mandatory pensions.
In 2011, the company acquired the assets of pension funds in other countries of the region, in 2013 the firm completed a merger process with a foreign group adding to its management portfolio of Pension and Unemployment Funds, life insurance, and administration of investments.
The technical difficulty and business involvement.
Currently, this Pension Fund management company has constant development of applications to retain its customers and also to be at the forefront of the business, therefore, currently with a large number of applications, these applications are grouped according to to the users who use it, there are two groups:
Internal applications or internally used applications of the company
Satellite-type applications are used mainly by affiliates who carry out self-management operations in the different existing channels according to their requirements and/or needs.
In satellite-type applications, the administrator must allow operations that by their nature require different security mechanisms such as authentication, identification, and authorization. However,
To achieve authentication, affiliates use the username and password mechanism.
The authorization is carried out through a system of roles, profiles, and permissions, all configured depending on the type of affiliate and the accesses they require to carry out their respective operations.
The identification of the affiliate is a more complex task, bearing in mind that the objective of this mechanism is to ensure that the user is really who they say they are and that they have not been impersonated.
This last identification mechanism is the core of the problem to be solved since it must allow the administrator to ensure that the affiliates carry out the procedures, operations, and/or use of services in a reliable and safe manner with the quality they deserve.
Now, the combination of different security factors adds more layers of security to the authentication procedure, providing robustness to the verification and making intrusion and identity theft by third parties more difficult. For them we introduce strong authentication, which is when combined with minus two factors to guarantee that the user who authenticates is really who he claims to be, all strong authentication is also a multi-factor authentication (MFA), where the user verifies his identity as many times as factors are combined, even if one of the factors fails or is attacked by a cybercriminal, there are more security barriers before the cybercriminal can access the information.
As a result of this, the “identity validator system” arises, which is the system as a service that performs the process of identifying the affiliates in the administrator, which is used by the other systems that require it so that they can decide whether or not they authorize the execution of a procedure.
Solution realized, AWS services, Architecture
To achieve a correct identification of the affiliate, the collection of data becomes evident as a first step, depending on these data, the best decision must be made as to which identification mechanisms should be applied, then these mechanisms must be applied, wait for the Affiliate response and verify it, in parallel the entire process consists of its respective operations and statistics record.
The general architecture of the system is essentially made up of the following components:
Satellite: they are those that consume the services of the identity validator system since they need to validate the identity of their affiliates before carrying out a procedure.
UI: Identity validator system graphical interface. Set of components and libraries developed in React JS that can be used by the Satellites, which contain the connection logic towards the identity validator system services.
APIGateway: Contains the endPoints that the identity validator system exposes
Traceability in Splunk: Components that are responsible for recording the messages it exchanges identity validator system (externally and internally)
Completeness: Component that is responsible for making the necessary calls to services external identity validator system that extract the necessary information from the client to make the decision of what mechanism will be applied.
Validate Pass: Component that is responsible for eliminating the mechanisms to be applied to the client those that have already been validated taking into account a series of configurable criteria.
Mechanism Manager: In charge of executing the mechanism and carrying out the validation through communication with third-party services and interpreting and validating their responses.
Rule Manager: In charge of making the decision of the mechanisms that will be applied to the client.
Architecture flow
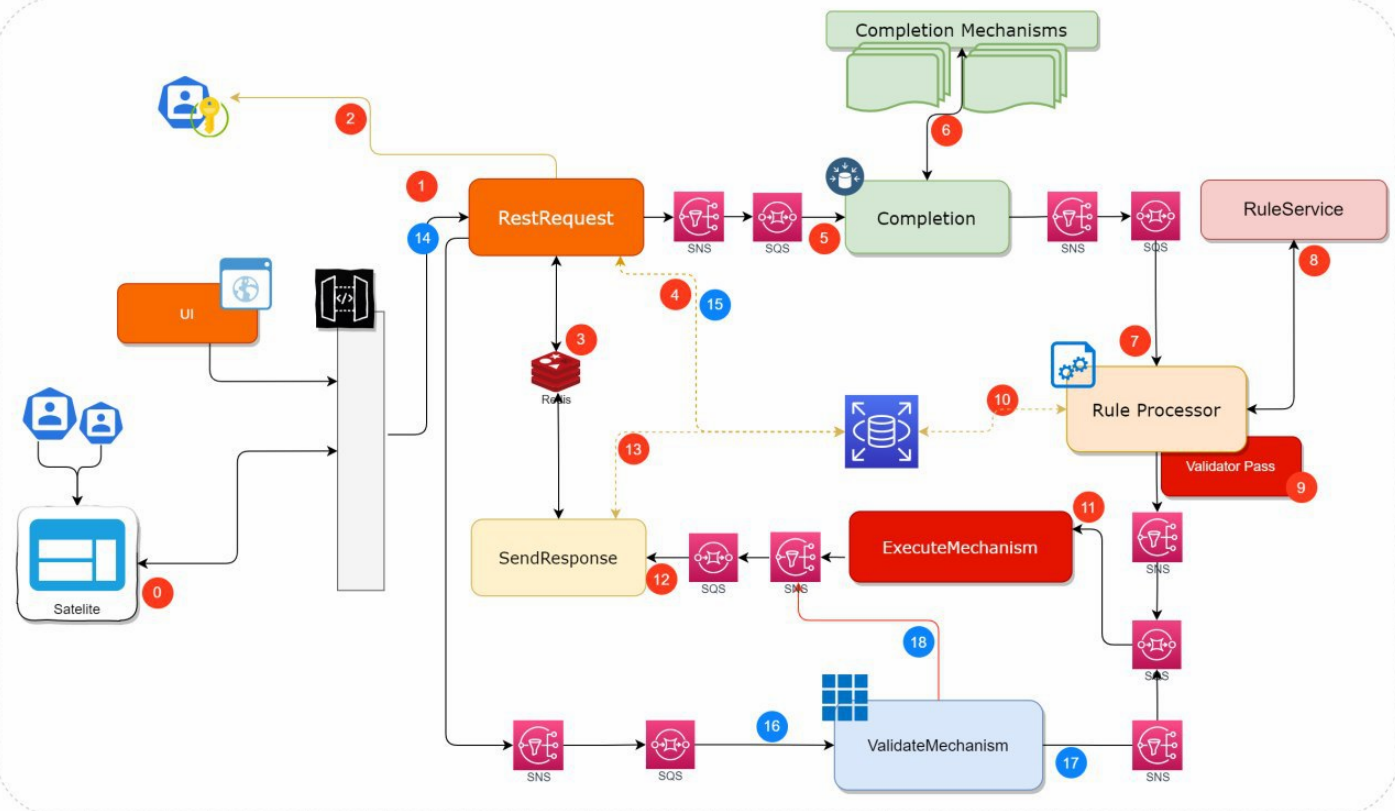
The identity validator system is a system made up internally by several micro-services that interact with each other. The general flow of the identity validator system consists of a request for validation of the mechanism for a client which travels through the different micro-services that make up the system. The following is the identity validator system message flow architecture.
The image shows, similar to the logical architecture of the identity validator system, the internal architecture of Micro-services using AWS SQS queues as an intermediate communication channel, which make up the system and the data flow of a request. that is performed at the same. The image flow is a functional flow which means that the request is not canceled.
The flow is described below:
The identity validator system receives a validation request from one of the corresponding channels and which are configured, validates the data sent according to a defined structure and request ID.
Authenticate the request according to the Satellite that is making it.
Register the information in Redis where it will keep waiting for the response for the Request ID (synchronization simulation)
Determines if it is an uninitiated request, validates if the transaction and the channel exist.
The process of completing the request data begins.
They are called the external completeness services of the identity validator system to extract the information required from the affiliate, which will be used in the decision-making of the identification mechanism that should be applied.
The completeness data is sent to the RuleProcessor micro-service, through the fan-out scheme and using SNS and SQS, which will be in charge of orchestrating the rules to determine the list of mechanisms to apply to the client.
They are determined by the data that was extracted in Completeness, plus the data of the initial Request itself, and taking into account a series of rules that the list of mechanisms to apply must be met.
The validations that the client has passed in a given time are determined
The necessary consultations are made to complete the required information
The completeness data and the list of mechanisms to be applied are sent to the ExecuteMechanism micro-service, which searches the list of mechanisms to apply for the first one that has not been validated and calls the external service to the identity validator system that starts the validation mechanism.
The collected data plus the response from the initiation of the first invalid mechanism is sent to SendResponse. This stores the entire request in the Database for subsequent requests.
Push the data into Redis where RestRequest is waiting to send the request-response
A validation request of the initiated mechanism is started. It keeps reading from Redis the answer.
It is validated that the start request has been executed correctly and that the request is valid
It is sent to validate the mechanism, where the validation service corresponding to the same initiated mechanism is called
It is verified that the validation has been successful and the mechanism is marked as valid in the list of mechanisms
Send invalid mechanism response
Low Level Architecture
A lower-level identity validator system architecture shows the complexity of the system and the number of components that intervene and interact with the Request information that travels from one micro-service to another; where each one is enriching and modifying its state.
What are the benefits of this solution for the client?
As part of the implemented solution, the client obtained greater security in the processes of self-management and operations that required verification of the identity of the person who required it. That In this sense, the consumption of the system was implemented in the satellites to make the decision whether to allow or not carry out operations, which brought a greater securitization of operations and prevents in a high degree spoofing. With this, it has gained greater prestige and confidence from affiliates knowing that there are ways to verify their identity when operating with their services and products of your day-to-day.
With a total of 131 participants (Colombia, Chile, and Peru), 3HTP concludes its first AWS IMMERSION DAYS held during the months of August and September. The acknowledgments and recommendations confirmed that the strategy outlined and the effort made paid off. We want to share the excellent results, challenges met, and experience gained in conducting these workshops.
A simple idea was the beginning of the results that we can see today. AWS proposed to 3HTP the opportunity to give an IMMERSION DAY related to the topic of Core Services of Amazon Web Services, however, it was considered that it was very positive to see the opinion of the customers and a survey was carried out that showed that 70% preferred the Kubernetes theme
Resultados encuesta Linkedin.
What differentiates these IMMERSION DAYS from those that were carried out previously.
CHALLENGES
Adapt an activity originally planned to be carried out in person for a long duration to a remote format.
How to achieve the interest, active participation and permanence of the participants throughout the activity.
Achieve continuous feedback from the participants throughout the activity to look for areas for improvement.
A methodology was designed for the delivery of the AWS IMMERSION DAY workshops to take an activity that was initially developed in-person to a 100% online modality.
Different steps were established that allowed each of these elements to be overcome and that sought to maintain the quality of the workshop and the satisfaction of the participants with the topic and the level of depth of the content.
Custom scheduling logistics.
Presentation of introductory concepts in a general session for Participants.
Division of work teams by instructor (7 to 10 people maximum) for personalized follow-up.
Progress validation through checkpoints by Instructors.
Progress control by the IMMERSION DAY coordinator asking the participants of the groups.
Survey at the end of the session to get early feedback.
The objective was to give an edition of the IMMERSION DAY of AWS KUBERNETES, however, the call presented 350 interested in the subject, so it was necessary to schedule several editions, including 2 workshops directed and exclusive to 2 companies in Colombia. (Grupo AVAL and AFP Protección).
CONTENT.
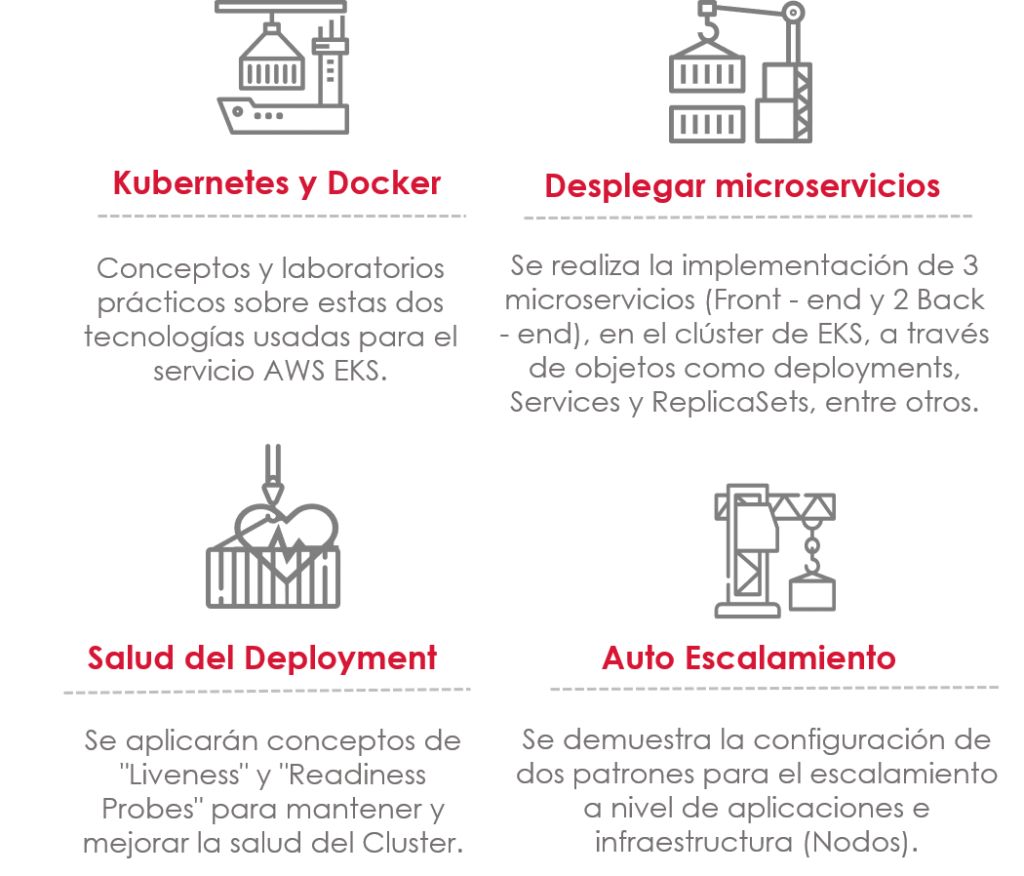
The objective of the KIMMERSION OF KUBERNETES is for participants to learn the concepts of containerization and orchestration and interact with guided hands-on workshops on the AWS EKS service.
Contenido del taller AWS IMMERSION DAY – KUBERNETES
RESULTS
A total of 5 AWS KUBERNETES IMMERSION DAYS Workshops were held:
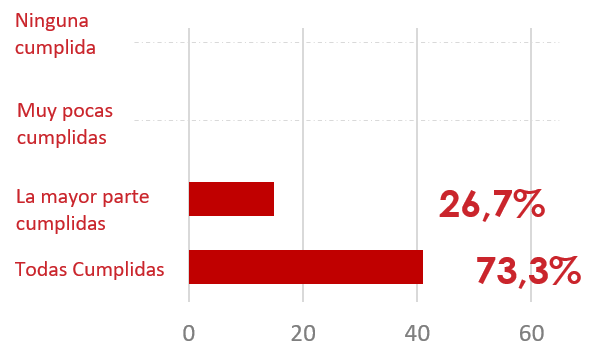
In the workshops held, 100% of the participants stated that their expectations were fully or partially met.
Cumplimiento de expectativas cumplidas
It is important to emphasize that the time for completion is one of the elements to take into account during the practical exercises. At this point, it is very favorable that the instructors keep their attention on the progress status of each participant.
In a relevant way, the satisfaction of the participants regarding the knowledge of the instructors and their follow-up during the workshops stands out, an element that was taken into account in the applied methodology.
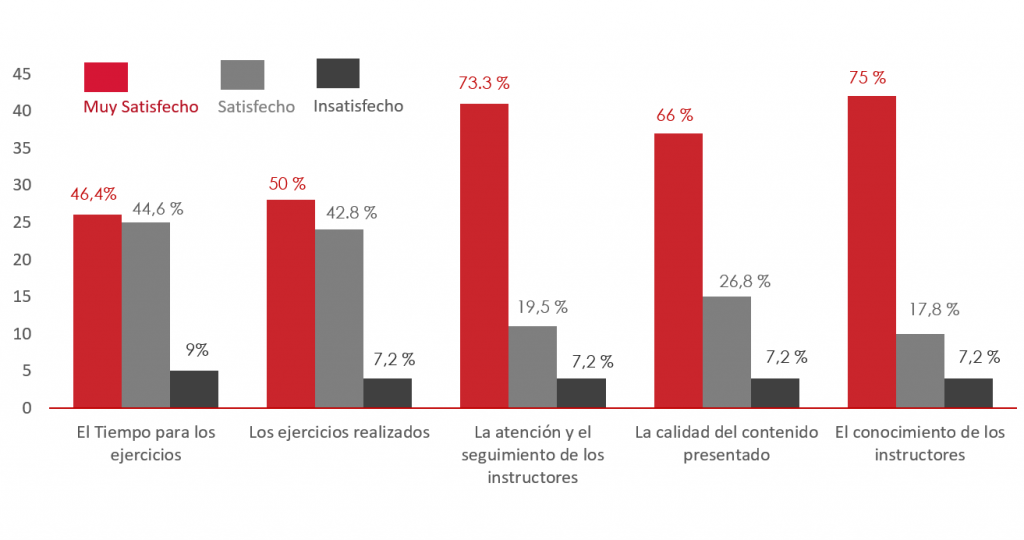
Por ciento de satisfacción de los participantes por cada item.
SOME RELEVANT COMMENTS FROM PARTICIPANTS
“Excellent activity, the instructor attentive to all doubts and demonstrating extensive knowledge of the exposed tools. I am pleasantly satisfied and I recommend them 100% “
Participant of IMMERSION DAY Colombia
“Excellent space and methodology combining concept with practice. Keep explaining the commands like Jonathan did .. because then one follows the lab understanding what is being done. It was very useful to advance in my study plan of these concepts and it generated a lot of value and progress in understanding these concepts. THANK YOU SO MUCH!!! “
Participante del IMMERSION DAY Colombia
“Perhaps the workshop could be done in two parts so that it is not so exhausting, but the workshop is excellent.”
Participant of IMMERSION DAY Perú
“Excellent Workshop, very dynamic, very clear, I was attentive and entertaining all the time, I learned new concepts. Thank you.”
Participant of IMMERSION DAY AFP Protección
LEARNED LESSONS
Experiences were obtained from each workshop held, as well as from the comments and suggestions of the participants. These elements helped us to see what needs to be improved for the next IMMERSION DAYS:
Have students share their screen if they are lagging behind, to ensure they can keep up with others.
Reinforce and guarantee that the steps of the initial Setup are fulfilled for the success of the other laboratories.
Profiling the audience to know their level of knowledge prior to IMMERSION and thus make groups with similar levels of knowledge, to personalize the co
WHAT DO YOU THINK? DO YOU WANT YOUR OWN IMMERSION DAY?
3HTP is an AWS Certified Partner to teach IMMERSION DAYS, it has Certified Architects that will help you to know and master the architecture of Amazon Web Service. We can organize an IMMERSION DAY workshop just for your company team.
AFP Protección S.A., a subcompany of the Colombian holding company Grupo de Inversiones Suramericana, is the second largest pension and severance fund manager in the country with nearly 1.6 million affiliates. AFP Protección S.A., a unit of the Colombian holding company Grupo de Inversiones Suramericana, is the second largest pension and severance fund manager in the country with nearly 1.6 million affiliates.
www.proteccion.com
PROTECCIÓN started with the application implementation project with Docker technology at the beginning of 2017, oriented at the time on totally OnPremise infrastructure that 3HTP accompanied from the administration of all its middleware platforms.
In 2018 PROTECCIÓN began with digital transformation plans aimed at discovering and implementing Cloud strategies and therefore undertook an analysis of the leading providers of this service in the market. At the same time, it began a call process to find container management services in the cloud, from the most important providers in the market and it was there that 3HTP offered Protection the option of an analysis of the AWS Amazon Elastic Container Service Container Management service (ECS).
Through the cooperative work between AWS and 3HTP, the client was proposed to carry out a proof of concept to show the functionalities and benefits of using the ECS container management services and in turn, as a good strategy for the client, it also began to show the compatibility, description, and integration with other cloud services that would allow PROTECCIÓN to take into account in the evaluation for its cloud service providers. Despite the fact that the client was already quite interested in the service delivered by another cloud provider, it was possible to demonstrate with the arduous technical work carried out in the implementation of an application as a test of functionality and scope, that AWS ECS would deliver a higher level solution and impact on your expectations for functionality and implementation.
PROTECCIÓN, finally convinced of the solution, granted the service tender to 3HTP-AWS and designated two relevant applications for its operation, to be migrated from containers deployed in the OnPremise environments to the AWS cloud.
After the designation of the project and at the request of one of the team leaders, an evaluation was started with the intention of expanding the scope of the project in terms of management technology, administration, and portability between clouds for cases requested by PROTECCIÓN and from there The option of implementing the use of Kubernetes with the AWS Amazon Elastic Kubernetes Service (EKS) service was proposed.