Case: “Embarking on a Digital Journey: Transforming from Manual to Automated Deployments”, Legops tech S.A.S

Introduction
Many organizations are focused on undertaking technology upgrades, and willing to improve their internal processes and project execution, to deliver superior experiences in performance, availability, and efficiency to their customers. However, tackling a technology upgrade, especially in the cloud environment, goes beyond mere willingness; it involves a solid commitment at both the organizational and managerial levels, aimed at implementing improvements that will be truly fruitful.
In this context, the automatic deployment of applications emerges as a practically indispensable requirement to ensure the high availability demanded by the current scenario. Manual processes of dependency installation and service execution are obsolete practices that belong to the past. This challenge is being enthusiastically taken up by several organizations seeking not only to remain competitive, but also to adopt best practices and focus on business strategies that benefit both the processes and the people who depend on them.
In this context of transformation, we highlight the key relevance of dockerization, using readme as a basis for this process. In addition, the implementation of Continuous Delivery (CI/CD) practices, supported by services such as AWS CodePipeline, stands as a cornerstone to accelerate and optimize development cycles, providing a continuous and reliable flow from code writing to production deployment. These strategies not only drive operational efficiency, but also lay the foundation for agile, future-oriented innovation in a constantly evolving technology environment.
About the customer
![]()
It is a company that provides professional virtual services for the legal world, where through its developments it helps its clients to more efficiently manage their legal matters, such as collaborative work, document signing, process traceability. Their clients are law firms and independent lawyers and companies that want to keep track of certifications, regulations, and legal processes through the use of technology.
Number of employees: 11-50
Age: 8 years
Customer Challenge
Phase 1: customer request
3HTP Cloud Services’ proposal for LEGOPS focuses on providing Specialized Technical Consulting and Support to optimize the architecture and operation model of its systems in AWS. In the initial phase, we address the review and improvement of the existing architecture, the implementation of environments and the empowerment of DevOps processes, including the creation of automation pipelines. This project is presented as a comprehensive commitment to elevate the operational efficiency and performance of LEGOPS, providing customized and certified solutions by DevOps and AWS experts.
Phase 2: proof of concept
A first phase of the project with LEGOPS, which should be considered for the context that will be explained later, is the phase in which the applications were dockerized. Here LEGOPS (hereinafter the client) showed the readme (informative document that indicates the necessary commands for the deployment and additional information) with which they deployed the applications and installed the necessary dependencies for the operation is these. In AWS but this was completely manual.
Here the Dockerfile files were built, containerization tests were performed exposing the applications locally and deployed in an AWS environment with the minimum requirements, which was preceded by the provisioning of an infrastructure in the cloud provider Amazon Web Service (AWS), where application container services, automated pipelines for change management at the development and deployment level (DevOps lifecycle), databases in the RDS service, compute capacity supported in the EC2 service and an EKS (Elastic Kubernetes Services) cluster for application management and scaling were implemented; a positive result was obtained from the initial requirements set forth by the LEGOPS client.
Phase 3: deployment in controlled environments
In phase 2, according to the success of the first phase, the opportunity arose to replicate what was done in that first phase in three different accounts (development, testing and production), which were done in a progressive and controlled manner that allowed fine- tuning the performance parameters in terms of computation, networks, security, database consumption and application availability. In addition, stress and performance tests were performed on the applications. The greatest gain of phase two was the knowledge generated that was delivered to the client and the capacity acquired by the 3HTP architects’ team.
Phase 4: production start-up
The last phase consisted of making available what was done in the 3 accounts, in a productive account to automate the life cycle of the 9 applications that the client has. Here the observations of the 3 controlled accounts were considered, a synchronization was made between Github and Codecommit for the versioning of the repositories, as additional measures CPS policies were created in Cloudfront, cookies optimization, JS libraries update and performance details that made more efficient the consumption of the applications.
Partner Solution
3HTP focused activities
The Customer, in collaboration with its teams of architects, administrators and developers, recognized in AWS a strategic partner to automate the deployment of its web applications.
In the context of this project, 3HTP Cloud Services played an active role in providing guidance, establishing key definitions and implementing technical solutions both in infrastructure and in supporting the development and automation teams.
3HTP Cloud Services’ participation focused on the following areas:
- Validation of the architecture proposed by the client.
- Deployment of infrastructure-as-code (IaC) projects on AWS.
- Implementation of automated processes and continuous integration/deployment (CI/CD) for infrastructure and microservices management.
- Execution of stress and load tests in the AWS environment.
This strategic and multi-faceted involvement of 3HTP Cloud Services contributed significantly to building a robust, efficient infrastructure aligned with AWS standards of excellence, thus supporting the overall success of the project.
Services Offered by 3HTP Cloud Services:
The organization already had an initial cloud adoption structure for its customer portal. Therefore, as a multidisciplinary team, we proceeded with an analysis of the present situation and the proposal made by the client. The following relevant suggestions for the architecture were derived from this comprehensive assessment:
- Differentiation of architectures for productive and non-productive environments.
- Use of Infrastructure as Code to generate dynamic environments, segmented by projects, business units, among others.
- Implementation of Continuous Integration/Continuous Delivery (CI/CD) practices to automate the creation, management, and deployment of both infrastructure and microservices.
Architecture
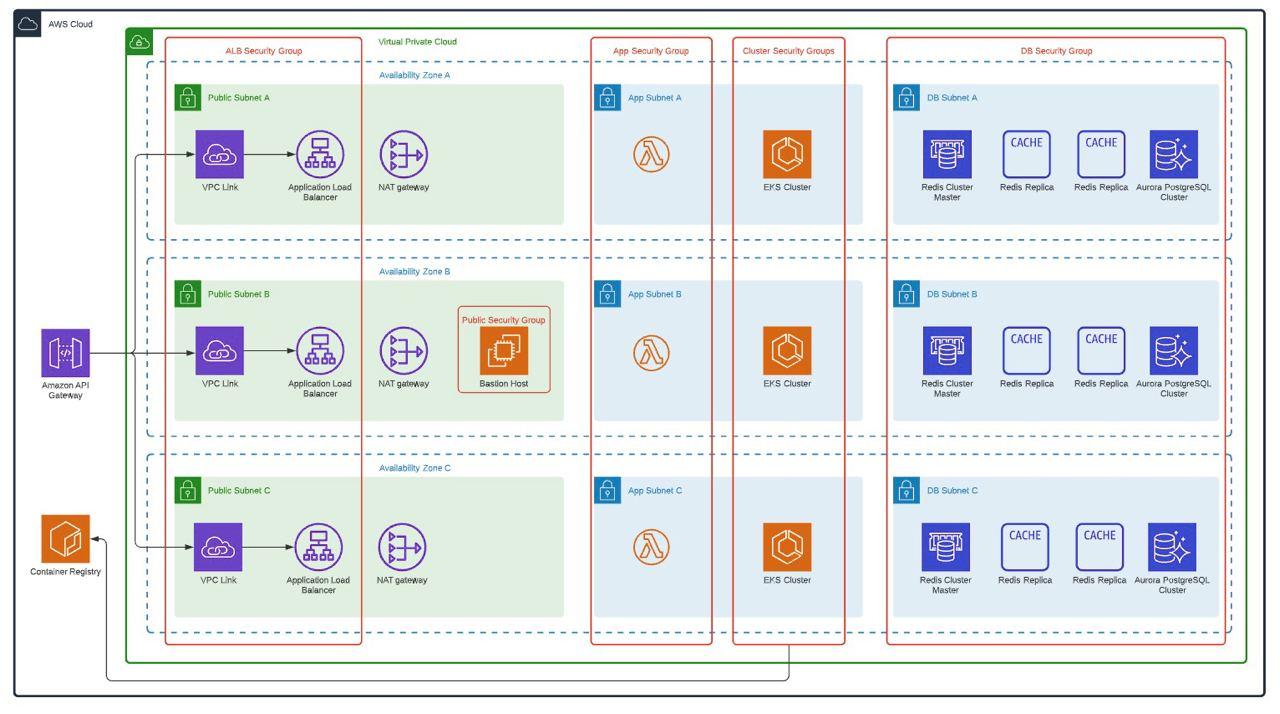
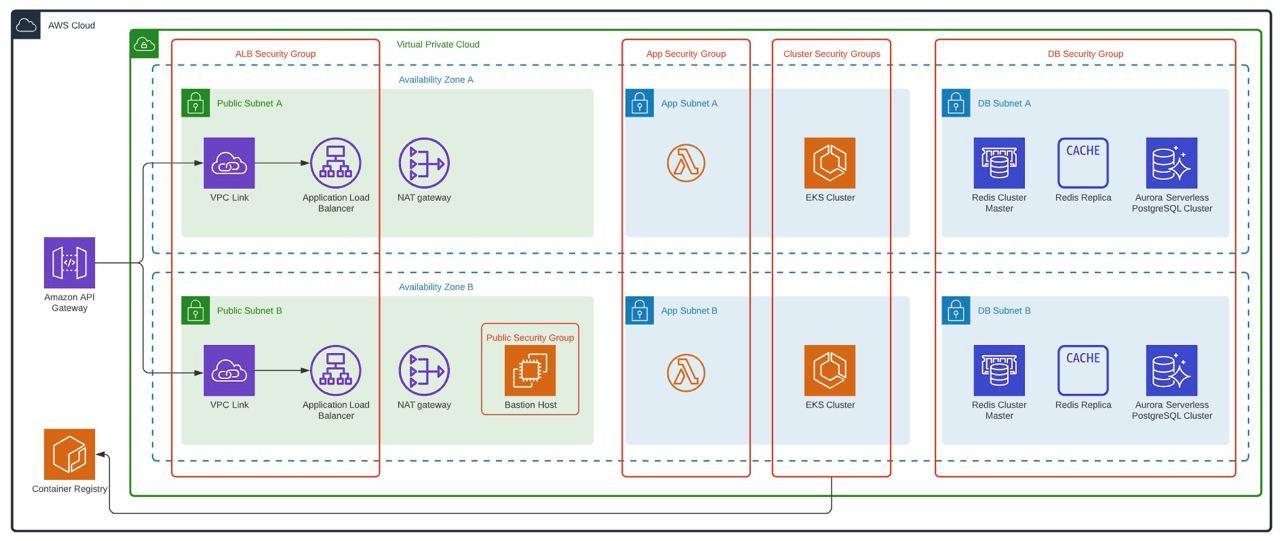
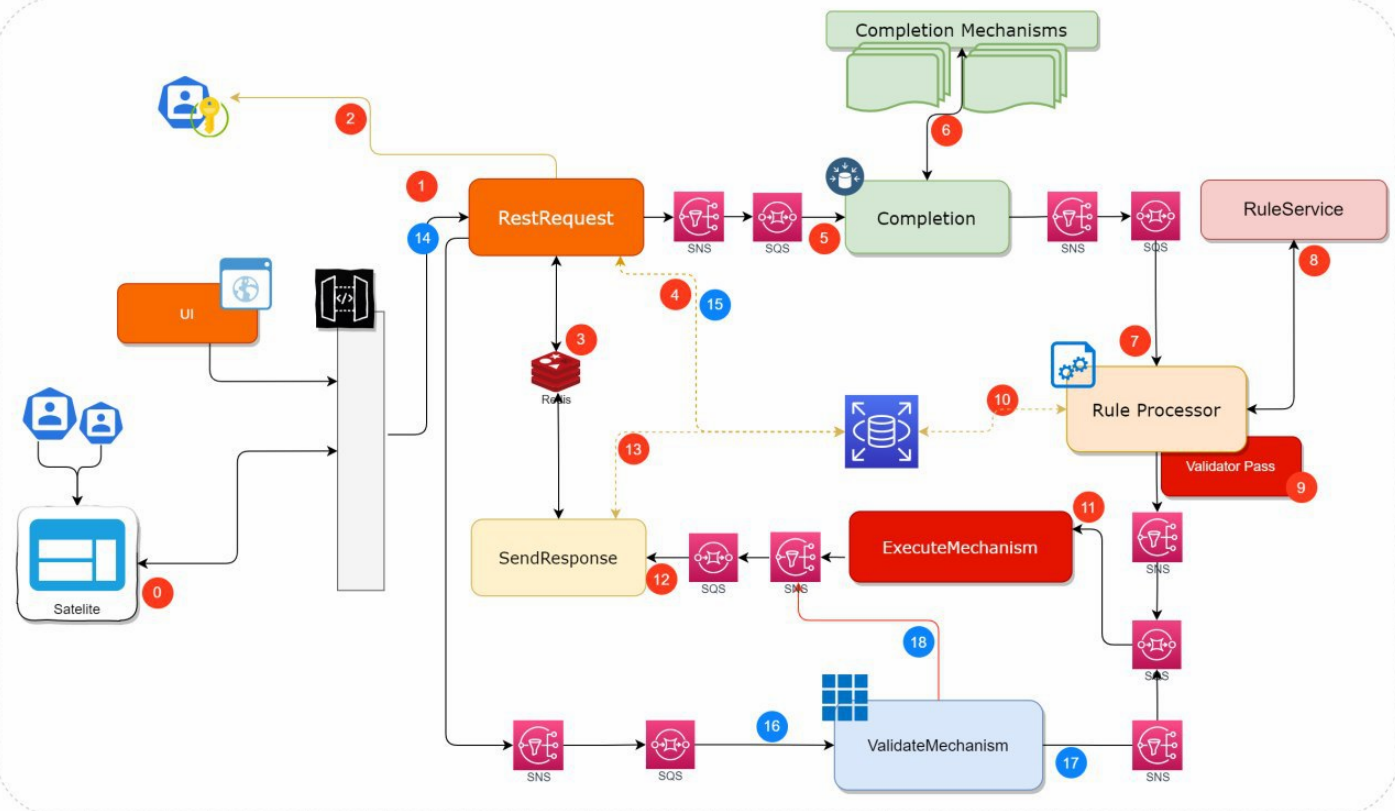
To replicate what was done in phase 1, the following architecture was proposed with all the immersed services used, which was received and approved by the client. This also has the best practices of AWS Well Architected where security, performance efficiency, operational excellence, reliability, cost optimization and sustainable architecture are protagonists.
Several services work together to support applications and data. Key services include Amazon S3 for secure file storage, Amazon CloudWatch for monitoring, and AWS IAM for access control. In addition, we use Amazon SQS for scalable and reliable message queuing between distributed application components. This facilitates asynchronous communication and improves overall system resiliency. In addition, SSL/TLS certificates were easily managed with AWS Certificate Manager, ensuring secure connections for applications and data.
The Virginia region hosts an ECR as a container image repository, which made it possible to efficiently manage and store Docker images for containerized applications. DevOps services such as AWS CodePipeline, CodeBuild, CodeCommit and CodeDeploy automate these software release processes, optimizing the deployment pipeline. AWS CloudFront serves as a content delivery network, optimizing content delivery to end users and is protected by AWS Web Application Firewall to defend against web-based attacks.
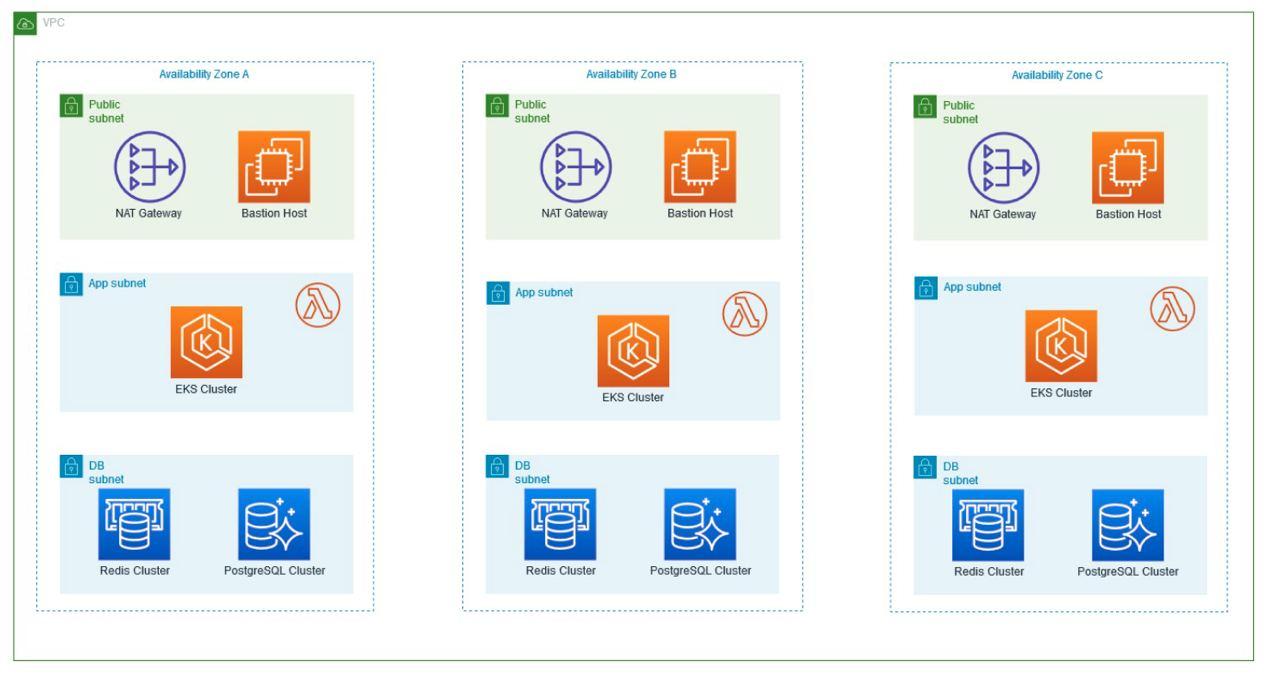
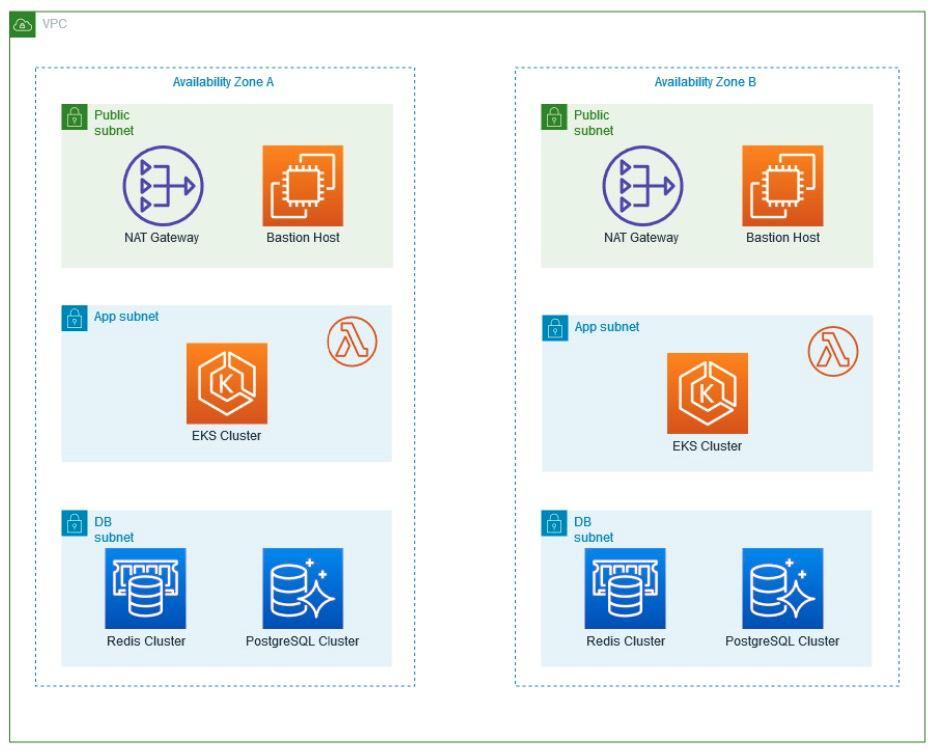
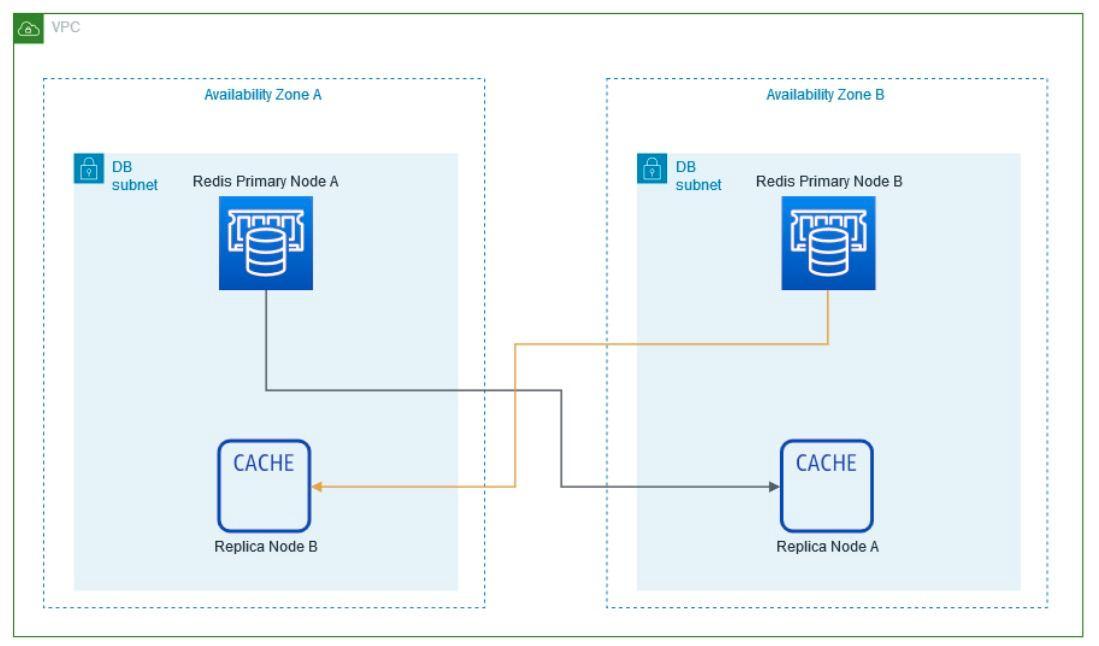
Within the Virtual Private Cloud (VPC) created, which spans two Availability Zones, there is an Internet gateway, a public subnet with an Application Load Balancer, and a secure EC2 instance known as “Bastion” for additional protection. Traffic is routed from the public subnet to the private subnets through a NAT Gateway. One private subnet hosts an Amazon RDS instance for database management and an OpenSearch service for search functionality. In addition, the second private subnet includes an EKS service, responsible for managing containerized applications, along with an auto-scaling EC2 worker node. All services within the VPC are protected by their respective security groups and interconnected via routing tables.

Used services
AWS Certificate Manager: ACM is a service that makes it easy for users to provision, manage and deploy SSL/TLS certificates for use with AWS services. It provides a simple way to secure network communications and encrypt data transmitted between clients and servers.
S3 (Simple Storage Service): S3 is a highly scalable and secure cloud storage service that allows users to store and retrieve data, such as files, documents, images, and videos, from anywhere at any time.
Amazon CloudWatch: CloudWatch is a monitoring and management service that provides real-time insights into the operational health of your AWS resources, helping you monitor metrics, collect, and analyze historical archives, and set alarm clocks.
AWS IAM (Identity and Access Management): IAM is a service that allows you to securely manage user access and permissions to AWS resources, allowing you to control who can access what is in your AWS environment.
Amazon SQS (Simple Queue Service): a fully managed message queuing service that enables decoupling and scaling of microservices, serverless applications and distributed systems, provides a reliable and scalable platform for sending, storing and receiving messages between software components, ensuring smooth and efficient communication.
ECR (Elastic Container Registry): ECR is a fully managed container image registry that simplifies the storage, management, and deployment of container images, providing a secure and scalable solution.
AWS CodePipeline: CodePipeline is a continuous integration and continuous delivery (CI/CD) service that automates your software release processes, allowing you to build, test and deploy your applications from trusted sources.
AWS CodeDeploy: CodeDeploy is a fully managed deployment service that automates application deployments to EC2 instances, on-premises instances and serverless Lambda functions, ensuring fast and reliable application updates.
AWS CodeBuild: CodeBuild is a fully managed build service that compiles source code, runs tests, and produces software packages, eliminating the need to maintain your build infrastructure.
CodeCommit: CodeCommit is a fully managed source control service that hosts secure and scalable Git repositories, allowing you to store and manage your code well.
AWS CloudFront CDN: is a global content delivery network (CDN) that accelerates the delivery of web content to end users around the world with low latency and high transfer speeds.
AWS Web Application Firewall: WAF is an AWS service that connects to AWS Cloudfront, helps protect your web applications from common web exploits and attacks. It allows you to define rules to filter and monitor HTTP and HTTPS requests to applications.
VPC (Virtual Private Cloud): VPC is a virtual network environment that allows you to create a private, isolated section of the AWS cloud, giving you control over your virtual network and allowing you to define IP ranges, subnets and network gateways.
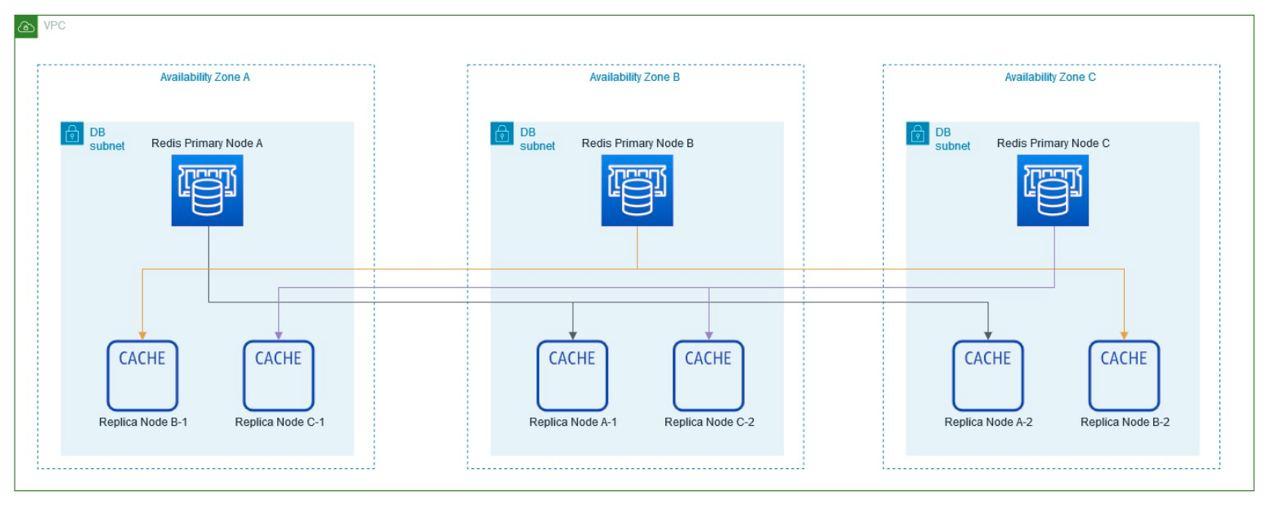
Availability Zones (AZ): Availability Zones are isolated locations within an AWS region that provide fault tolerance and high availability. They are interconnected with low latency links to support resiliency and redundancy.
Internet Gateway: Internet Gateway is a horizontally scalable gateway that enables communication between your VPC and the Internet, allowing you to access resources in your VPC from the Internet and vice versa.
Routing tables: Routing tables are rules that govern network traffic within a VPC, allowing you to manage the flow of data between subnets and control connectivity to the Internet and other resources.
EC2 (Elastic Compute Cloud): EC2 provides scalable virtual servers in the cloud, known as EC2 instances. It allows you to quickly launch and manage virtual machines with various configurations, providing flexible and resizable compute capacity for your applications.
Application Load Balancing: ALB is an AWS load balancing service that evenly distributes incoming application traffic across multiple destinations, improving scalability, availability, and responsiveness. It supports advanced features such as content-based routing and SSL/TLS termination.
AWS OpenSearch Service: AWS OpenSearch is a fully managed, highly scalable, open-source search service based on the Apache OpenSearch project. It simplifies the deployment and management of search functionality within your applications.
RDS (Relational Database Service): RDS is a fully managed relational database service that simplifies the configuration, operation and scaling of relational databases. It supports popular database engines and provides automated backups, patching and high availability for reliable and scalable data storage.
EKS (Elastic Kubernetes Service): EKS is a managed Kubernetes service that simplifies the deployment and scaling of containerized applications. It automates the management of the underlying Kubernetes infrastructure, allowing you to focus on developing and running your applications efficiently.
Security Groups: Acting as virtual firewalls, security groups provide granular access control for instances by defining authorized protocols, ports and IP ranges, ensuring secure inbound and outbound traffic.
Infrastructure as code
A significant advantage of this technology refresh and paradigm shift lies in the adoption of Infrastructure as Code (IaC). Previously, our client was manually managing its entire infrastructure through the AWS console and command line interface (CLI), which presented considerable challenges in terms of scalability and operational agility.
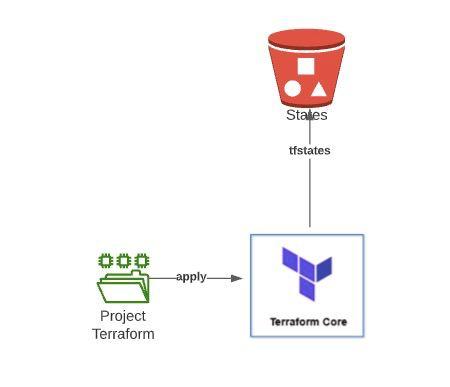
Manual management became increasingly complex as the infrastructure grew, as upgrades and modifications required manual interventions that slowed down the process. Implementing Terraform was a significant change, allowing us to create a project where, through code, planning, building and destroying infrastructure in the AWS cloud became as simple as a click, giving precise control over every action.
With Terraform, we have achieved more efficient and agile infrastructure management, overcoming the limitations of manual administration. This code-based approach not only improves speed and consistency in resource deployment, but also provides greater flexibility to adapt to changes in scale and the demands of the evolving technology environment. In summary, the adoption of IaC, through Terraform, has enabled our client to optimize their infrastructure on AWS in an effective and simplified manner.
Terraform
Terraform is an IaC (Infrastructure as Code) technology that allows us to define and maintain through configuration files using HCL (Hashicorp Configuration Language, a domain-specific language developed by them) all our infrastructure deployed through different cloud providers (AWS, Azure, GCP, etc). Also in on-premise installations, as long as we expose an API through which Terraform can communicate.

Code commit and Github
In our ongoing commitment to adapt to the specific needs of our clients, we implemented a synchronization process between GitHub and CodeCommit. Recognizing the importance of flexibility and efficient collaboration in software development, this strategic integration allowed our client to take advantage of the best of both platforms.
GitHub, known for its robust community and collaborative tools, integrated with CodeCommit, the AWS version control service, to streamline repository management and facilitate collaboration across distributed teams. This hybrid approach not only improved workflow efficiency, but also ensured greater security and compliance with industry standards.
By implementing this synchronization between GitHub and CodeCommit, our client experienced improved synergy in software development, allowing for agile collaboration and accurate version tracking. As such, the client was able to continue their workflow as normal while changes were reflected in AWS Codecommit.
Dockerization of applications
Docker, a cornerstone of modern application management, represents an open-source platform that simplifies application containerization. By encapsulating applications and their dependencies in lightweight, self-contained containers, Docker provides a standardized solution for efficiently packaging, distributing, and running software. Containerization allows applications to operate in a consistent and isolated environment, ensuring reliability from development to production. Docker stands out for its ability to simplify deployment, improve scalability, and optimize application management, making it an essential tool for development and operations teams.
Application containerization using DockerFiles represents a crucial step towards portability and consistency in software development. By using DockerFiles, the application’s runtime environment is described, facilitating its uniform deployment across multiple environments, including development, test and production. This approach provides a solid foundation to ensure that applications run reliably, regardless of differences between environments. Containerization with DockerFiles not only simplifies dependency management, but also streamlines the development cycle by eliminating concerns related to environment variations.
How did we do it?
In response to the need to optimize the deployment of our client’s web applications, we undertook a significant transformation through the containerization of their applications. Initially, we observed that the manual deployment process, which involved the installation of dependencies through specific commands, resulted in a considerable investment of time and effort.
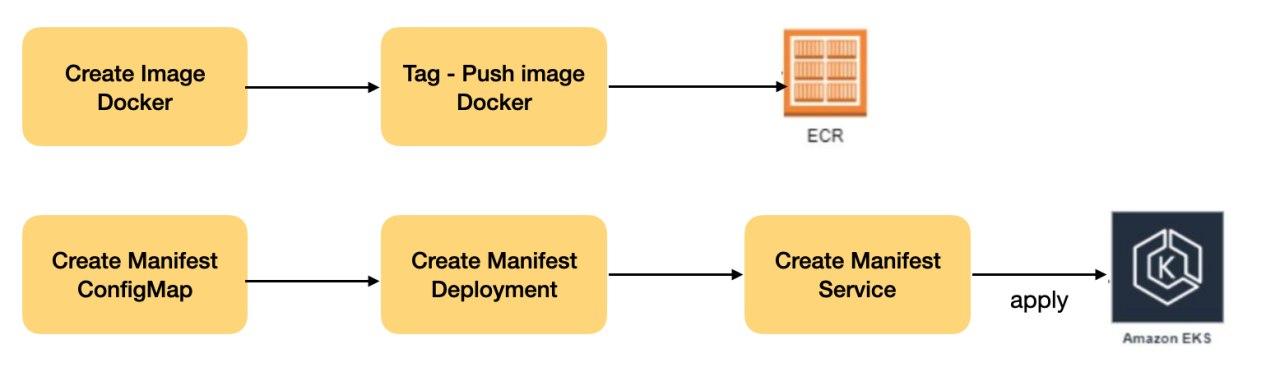
To address this issue, we dove into the existing README files of the applications, taking advantage of the detailed information provided there. We implemented a containerization process that encapsulates each application in separate Docker containers. This approach allowed our client to eliminate the tedious manual tasks associated with installing dependencies and configuring the environment, significantly simplifying the deployment process.
Containerization not only accelerated deployment, but also brought an additional level of consistency and portability to the applications. Now, with container images ready for deployment, our customer can deploy new versions and upgrades more quickly and confidently, reducing the risk of errors associated with manual methods.
We are pleased to have delivered a solution that not only improves operational efficiency, but also lays the foundation for a more agile and scalable deployment in the future. Containerization has proven to be a key strategy for modernizing and optimizing development and deployment workflows, putting our client in a stronger position to meet the dynamic challenges of today’s technology environment.
Environment configuration files
Environment configuration files complemented the Dockerfiles containerization, adding a crucial layer of flexibility. These files contain environment variables and settings specific to each environment, such as development, test, or production. By separating the configuration from the source code, Environment configuration files enabled easy adaptation of the application to different contexts without requiring modifications to the source code. This not only improves the portability of the application, but also ensures a flexible and secure configuration that can be managed independently throughout the development and deployment lifecycles.
Publication of Docker images in ECR
After having the applications containerized, and images ready they were published to the Amazon Elastic Container Registry (ECR) and is an essential part of the lifecycle of containerized applications. This process involved storing and managing Docker container images in a highly scalable and secure repository. Opting for ECR ensured the availability of the images.
ECR not only acted as a centralized repository for images, but also provided secure access control and retention policies, ensuring integrity and efficiency in image lifecycle management. In addition, its native integration with other AWS services simplified the implementation and ongoing deployment of applications, allowing client development teams to focus on innovation and development, without worrying about the logistical management of images.
This approach not only addresses security and availability, but also improves image version traceability, crucial for maintaining consistency and integrity in development and production environments.
AWS EKS Configurations
In the process of deploying containerized applications, hosted in the AWS Elastic Container Registry (ECR), we play a crucial role in creating thorough Kubernetes manifests and services to orchestrate the execution of these containers. Kubernetes manifests represent the very essence of application orchestration in containerized environments.
These YAML files serve as detailed documents that describe and define the configuration and resources required to deploy applications on a Kubernetes cluster. By addressing crucial elements such as deployments and services, Kubernetes manifests provide comprehensive guidance for Kubernetes to efficiently orchestrate and manage applications.
In particular, the creation of deployments is a fundamental part of this process. Deployments in Kubernetes allow us to define and declare the desired state of applications, managing the creation and update of the corresponding pods. This feature is essential to ensure the availability and scalability of our containerized applications.
In addition, exposing services is another crucial aspect. By creating services in Kubernetes manifests, we establish an abstraction layer that facilitates communication between different components of client applications. This allows external or internal users to access applications in a controlled and secure manner.
The declarative nature of manifests means that developers can define the desired state of their applications, allowing Kubernetes to interpret and act accordingly. These files not only make deployment easier, but also ensure consistency in application management, regardless of the complexity and scale of the cluster.
By leveraging Kubernetes manifests, teams can ensure efficient management and seamless deployment of applications in container-based environments. This consolidates operations and simplifies application lifecycle management, bringing greater reliability and stability to the automated deployment ecosystem.
Automatic CI/CD deployment
CodePipeline Deployment
We set up an end-to-end workflow using AWS development and deployment tools, specifically AWS CodePipeline, AWS CodeBuild and AWS CodeDeploy. This integration enables seamless continuous delivery (CI/CD), allowing us to deliver fast and secure updates to your application.
Continuous Integration and Continuous Delivery (CI/CD) pipelines represent an essential framework for efficient automation of the entire application development and deployment process. Designed to optimize code quality and delivery speed, these pipelines provide a complete solution from change integration to continuous deployment in test and production environments.
Continuous Integration (CI)
CI pipelines automatically initiate testing and verification as soon as changes are made to the source code. This ensures that any modifications are seamlessly integrated with existing code, identifying potential problems early and ensuring consistency in collaborative development.
Continuous Delivery (CD)
The Continuous Delivery phase involves automating deployment in test and production environments. CD pipelines enable fast and secure delivery of new application releases, reducing cycle times and improving deployment efficiency.
AWS CodeBuild: We configure custom build environments that match the specific requirements of your web applications. Builds are automatically triggered when there are changes to the repository, ensuring consistency and availability of deployment artifacts.
AWS CodeDeploy: We implemented a deployment group that ensures a smooth and gradual deployment. Monitoring policies were configured to automatically revert the deployment in case problems are detected.
AWS CodePipeline: We have created a customized pipeline that mirrors your development process, from source code retrieval to production deployment. The pipeline consists of several stages, including source code retrieval from your repository, building the application with AWS CodeBuild, and automated deployment using CodeDeploy.

Result and Benefits
- Rapid Continuous Delivery: With full automation, updates are deployed faster, improving delivery time for new features and bug fixes.
- Greater Confidence: Gradual implementation and automatic rollback policies ensure greater confidence in the stability of new versions.
- Visibility and Monitoring: Detailed monitoring dashboards were implemented to provide a complete view of the implementation process, making it easier to identify and correct problems.
- Refinement and definitions of standards to be used in the infrastructure.
Cloud Front
As a cloud services company, we provisioned Amazon CloudFront on AWS for our client, a solution that optimizes the delivery of web content quickly and securely. In addition, we implemented Crucial Preloaded Security (CPS) and HTTP Strict Transport Security (HSTS) policies to strengthen the security and reliability of the system.
CPS policies ensure greater protection by establishing predefined rules to mitigate known threats, thus guaranteeing a more attack-resistant environment. On the other hand, the implementation of HSTS adds an additional layer of security by forcing exclusive communication over HTTPS, preventing possible attacks such as downgrading to HTTP. These measures not only optimize content delivery, but also reinforce security, meeting the highest standards in data protection and user experience.
AWS SQS
As a leading cloud services company, we successfully implemented Amazon Simple Queue Service (SQS) to optimize our client’s application architecture. SQS, a managed messaging service, has allowed us to decouple and scale critical components, improving the efficiency and reliability of their systems.
By adopting SQS, we apply the “First In, First Out” (FIFO) principle to ensure sequential processing of messages in the order in which they were placed in the queue. This is crucial in applications where sequentiality and time synchronization are essential, such as in order systems and transaction processing, in this specific case for customer applications such as electronic signature of documents and traceability of legal matters.
Nginx-Ingress-Controller
We have successfully integrated NGINX into our client’s architecture, empowering their web applications with a robust, multi-functional server. NGINX not only excels as an open source web server, but also plays essential roles as a reverse proxy, load balancer and cache server. Its efficient architecture improves both the performance and security of web applications, making it the ideal choice for handling large volumes of concurrent connections.
In addition, we have implemented the NGINX-specific Ingress Controller as an integral part of Kubernetes environments. This component manages HTTP and HTTPS traffic rules, using NGINX to direct traffic to services deployed in the cluster. By configuring Ingress rules, such as routes and redirects, the Ingress Controller optimizes the efficient exposure and management of web services. The specific implementation of NGINX enhances security and efficiency, offering a complete solution for the controlled exposure of web services, thus contributing to the construction of modern and scalable architectures in container-based environments.
Stress and load testing for AWS implementation
We conducted extensive testing on our client’s applications to ensure optimal performance in a variety of situations. These tests included:
- Stress Testing: Focused on evaluating how applications handle extreme situations or sudden load peaks. Conditions that exceed normal operating limits are simulated to identify potential failure points and ensure stability under stress.
- Load Tests: Designed to evaluate the behavior of applications under sustained and significant loads. These tests seek to determine the capacity of applications to handle constant demand, identifying possible bottlenecks and optimizing resources for continuous performance.
- Performance Testing: Focused on measuring the speed and efficiency of applications under normal conditions. System response to various operations is evaluated to ensure fast loading times and a smooth user experience.
These tests allowed us to identify areas for improvement, optimize resources and ensure that applications perform reliably under various circumstances. Our dedication to comprehensive testing reflects our commitment to delivering technology solutions that are not only robust but also highly efficient and capable of adapting to the changing demands of the environment.
Benefits obtained by the customer
The adoption of advanced containerization and orchestration solutions has significantly transformed the technology landscape for our client. After dockerizing their applications and leveraging key services such as Kubernetes on Amazon EKS, automated deployment with AWS Pipelines, and strategic implementation of services such as CloudFront, SQS, along with robust security measures and a distributed VPC infrastructure across multiple availability zones, our client has experienced several notable benefits.
Scalability and Efficiency: Containerization with Docker and orchestration using Kubernetes in EKS has allowed our client to scale their applications efficiently, dynamically adapting to changing traffic demands without compromising performance.
Continuous and Automated Deployment: The implementation of AWS Pipelines has facilitated continuous and automated deployment, streamlining the development lifecycle and enabling fast and secure delivery of new features and updates to applications.
Performance Optimization: The use of CloudFront has significantly improved the delivery of web content, reducing load times and providing a faster and more efficient user experience across the board.
Efficient Message Handling: SQS has optimized message handling, enabling seamless communication between different application components, ensuring reliability and consistency in data processing.
Robust Security: The implementation of advanced security measures, within a well- structured VPC distributed across multiple availability zones, has strengthened data protection and application integrity against potential threats.
High Availability and Fault Tolerance: The distribution of the infrastructure in several availability zones has improved availability and fault tolerance, ensuring service continuity even in adverse situations.
Together, these solutions have enabled our client not only to improve operational efficiency and security, but also to offer an enhanced and scalable user experience, consolidating its position in a constantly evolving technological environment.
Conclusions
In conclusion, the road to a successful technological upgrade proves to be a fundamental journey for modern organizations. Beyond mere aspiration, it requires a solid commitment and a strategic vision that allows the implementation of truly fruitful improvements. In this context, the automatic deployment of applications is an indispensable component to ensure the high availability demanded by today’s dynamic landscape.
Abandoning obsolete practices and embracing dockerization, using readme as a guide, has emerged as a fundamental step in this evolution. In addition, the adoption of Continuous Delivery (CI/CD) practices, supported by innovative services such as AWS CodePipeline, emerges as a cornerstone to accelerate and optimize development cycles. This approach not only drives operational efficiency, but also lays the foundation for agile, future-oriented innovation in a constantly evolving technology environment.
By highlighting the relevance of strategies such as dockerization and CI/CD implementation, these organizations not only seek to remain competitive, but also to adopt best practices. Thus, they are orienting their efforts towards business strategies that not only benefit internal processes, but also the people who depend on them. In this context of transformation, technological evolution is not only a requirement, but an opportunity for growth and excellence in the delivery of advanced technological solutions.